見に来てくれてありがとうございます!石川さんです♪
最近PyScriptの使ってみた記事が流れてきて、サイトのドキュメントを読んだり、チュートリアルを作ってみたり、サンプルを動かしてみたりと、色々気になっていたので、思い切って買いました。他には書籍がなく唯一の本です。
さあ、読むぞ〜!
読んだらまとめ記事を発表しますね。

ということで一緒に極めましょう!データベース論理設計(業務分析)が趣味のようになってしまったシステム開発のスペシャリストです。パフォーマンスチューニングも得意です。システムにおける様々な問題を解決していますので、それらを共有できればと思います。
見に来てくれてありがとうございます!石川さんです♪
最近PyScriptの使ってみた記事が流れてきて、サイトのドキュメントを読んだり、チュートリアルを作ってみたり、サンプルを動かしてみたりと、色々気になっていたので、思い切って買いました。他には書籍がなく唯一の本です。
さあ、読むぞ〜!
読んだらまとめ記事を発表しますね。
見にきてくれて、ありがとうございます。石川さんです。
先日、仕事をしていたら、実行時エラーの原因となった関数に再び出会いました。このときに参考までに作った関数と比較して、はて、これってどっちの関数が速いのでしょうか、と、言うのが疑問に浮かびましたので、実測してみます!
先日紹介した自作関数(Number2Letter)は以下の通り、エクセルのセルのAddress関数を使用して求めていました。
'*****************************************************************
'*関数名 :Number2Letter
'*機能概要:入力されたカラム位置の数値からカラム文字の英数字に変換します
'*引数 :カラム位置(1~16384)
'*戻り値 :カラム文字
'*****************************************************************
Function Number2Letter(iCol As Integer) As String
Number2Letter = Split(Columns(iCol).Address(True, False), ":")(0)
End Function
そして、その時にぱっと作ったのが以下の関数です。名前が重複しないよう「2」を付けました。
Function Number2Letter2(iCol As Integer) As String
If iCol < 1 Then Number2Letter2 = "": Exit Function
Number2Letter2 = Number2Letter2(Int((iCol - 1) / 26)) & Chr(Asc("A") + ((iCol - 1) Mod 26))
End Function
なんと、再帰関数を使っております。かっこいい!あ、自画自賛になってしまった。。。
このポストを書いているうちに、作った関数は正しいのかな、という疑念が湧いてきたので、まずはテストしてみます。テストスクリプトと結果は以下の通りです。ちなみに、16384はエクセルの列番号の上限です。
Sub test()
Dim i As Integer
Debug.Print "チェックを開始します。"
For i = 1 To 16384
If Number2Letter(i) <> Number2Letter2(i) Then
Debug.Print "エラーです!", Number2Letter(i), Number2Letter2(i)
Exit Sub
End If
Next i
Debug.Print "エラーは無かったようです。"
End Sub
チェックを開始します。 エラーは無かったようです。
このとおり、特に問題はありませんでした。
はい、色々とああでもないこうでもないと言っている時間がもったいないので、まずは実測してみます。秒未満の時間を測る方法を失念したため、ググってこちらを参考にさせていただきました。今は見られませんが、会社に置いてある書籍にはGetTickCountが紹介されていたように思います。GetTickCountは1ミリ秒、TimerはSingle型の場合は0.01秒(10ミリ秒)でDouble型の場合は0.00000001秒(10ナノ秒)なので、何となくTimerをDoubleにして使うのがよさそうです。(と、思ってTimerをDoubleにして使ってみた結果からは10進数でいくと50ナノ秒が最小で間違いなかったと思ったのですが、よく見ると実際は、内部的に2進数を利用しているため、2^-8(0.00390625)が最小のようです。もしGetTickCountがもっと細かく出力されるのであれば、ミリ秒のGetTickCountを使うのが一番よかったのかも知れませんね。ただ、まあ誤差ですよねぇ。)
トライアンドエラーで最終的に、実測用のスクリプトと実行結果は以下のとおりになりました。さて、どちらが速いでしょうか?
Sub 計測()
Dim start, diff, total As Double
Dim i As Integer, j As Integer
Debug.Print "##### テスト1計測開始 #####"
total = 0
For j = 1 To 10
start = Timer
For i = 1 To 16384
buf = Number2Letter(i)
Next i
diff = Timer - start
Debug.Print "time : " & Format(diff, "0.00000000") & "秒"
total = total + diff
Next j
Debug.Print "Total : " & total & "秒"
Debug.Print
Debug.Print "##### テスト2計測開始 #####"
total = 0
For j = 1 To 10
start = Timer
For i = 1 To 16384
buf = Number2Letter2(i)
Next i
diff = Timer - start
Debug.Print "time : " & Format(diff, "0.00000000") & "秒"
total = total + diff
Next j
Debug.Print "Total : " & total & "秒"
End Sub
##### テスト1計測開始 ##### time : 0.07812500秒 time : 0.07421875秒 time : 0.07031250秒 time : 0.07031250秒 time : 0.07421875秒 time : 0.08593750秒 time : 0.07812500秒 time : 0.07812500秒 time : 0.07031250秒 time : 0.07812500秒 Total : 0.7578125秒 ##### テスト2計測開始 ##### time : 0.01953125秒 time : 0.01953125秒 time : 0.01562500秒 time : 0.02343750秒 time : 0.02343750秒 time : 0.01562500秒 time : 0.01562500秒 time : 0.01953125秒 time : 0.01953125秒 time : 0.01953125秒 Total : 0.19140625秒
結果にはまあまあの誤差があるように思えたので1~16384の変換をそれぞれ10回ずつ実行してみました。トータルで、およそ4倍の差があることになりました。4倍というと大きな差の用に感じますが、16万回実行して、0.56640625秒の差、ということなので、データ量によりますが、ほとんどのケースでは誤差と考えても問題なさそですね。
今回の実験をする前に、仕事のマクロを実行していた時に、処理に関係のないエクセルファイルを4つほど開いて実行したところ、処理が結構遅くなった事件がありました。もしかしたらオブジェクトがどのオブジェクトを差しているのかを調べるのに時間がかかっているのかも知れない、ということで、今回の関数で使用している「Columns」に着目しました。
実は、この「Columns」は、Sheet1.Columnsのことでした。そこで、今回の続きとして、Sheet1を記載した場合としなかった場合の差を計測してみたいと思います。
? Columns.Parent.name ' ? は、debug.Print と同義 Sheet1 ? Sheet1.Parent.name どっちが速い?.xlsx
ワークシートを指定するようにして、先ほどのNumber2LetterをNumber2Letter3として作成して同様に実行結果を比較してみました。計測2は、ミリ秒単位で計測するよう修正しました。さて、結果や如何に?
Function Number2Letter3(iCol As Integer) As String
Number2Letter3 = Split(Sheet1.Columns(iCol).Address(True, False), ":")(0)
End Function
Sub 計測2()
Dim start, diff, total As Double
Dim i As Integer, j As Integer
Debug.Print "##### テスト3計測開始 #####"
total = 0
For j = 1 To 10
start = GetTickCount()
For i = 1 To 16384
buf = Number2Letter(i)
Next i
diff = GetTickCount() - start
Debug.Print "time : " & Format(diff, "####") & "ミリ秒"
total = total + diff
Next j
Debug.Print "Total : " & total & "ミリ秒"
Debug.Print
Debug.Print "##### テスト4計測開始 #####"
total = 0
For j = 1 To 10
start = GetTickCount()
For i = 1 To 16384
buf = Number2Letter3(i)
Next i
diff = GetTickCount() - start
Debug.Print "time : " & Format(diff, "####") & "ミリ秒"
total = total + diff
Next j
Debug.Print "Total : " & total & "ミリ秒"
End Sub
##### テスト3計測開始 ##### time : 94ミリ秒 time : 78ミリ秒 time : 78ミリ秒 time : 78ミリ秒 time : 78ミリ秒 time : 109ミリ秒 time : 78ミリ秒 time : 78ミリ秒 time : 79ミリ秒 time : 93ミリ秒 Total : 843ミリ秒 ##### テスト4計測開始 ##### time : 78ミリ秒 time : 79ミリ秒 time : 78ミリ秒 time : 78ミリ秒 time : 78ミリ秒 time : 78ミリ秒 time : 78ミリ秒 time : 78ミリ秒 time : 78ミリ秒 time : 79ミリ秒 Total : 782ミリ秒
ホントに微差ですが、改善しました。
意外にも思い付きで作成した再帰関数の方が速くて驚きました!少量のデータの場合はあんまり気にする必要はありませんね。ただもし大量にデータを処理する必要がある場合は、再帰で定義した関数を使いましょう!
こんにちは、石川さんです。ときどきうまく動かないことがあるんです、と、言われちゃいました。何のことかって?当然、プログラムですよ!こうしたらこうなる、という再現性がある不具合は解決しやすいのですよ。再現性がないときにどうするか、っちゅう話ですね。
データ受信したときに、その日の夕方に自動的に返信するためにタスクスケジューラに登録しておく、というプログラムを用意したのですけど、だいたいはうまくいっているのに、たまにデータが返信できていないことがある、ということで、調査ですね。とりあえずは再現待ちということだったのですが、先日再現しました、と、ご連絡をいただきました。
まずは、タスクスケジューラにタスクが登録されているのかどうか、タスクスケジューラで確認しました。ありません。。。タスクは登録されていないし、実行もされていませんね。過去には実行された形跡がありました。
何か失敗していたら、イベントビューアに記録が残っているかもしれない、と、確認してみましたが、、、こちらもありません。タスクが実行されていないので、そりゃ何もないのが普通か。ただ、タスクスケジューラを実行したときに、何かの問題があって、ということであれば、何かが記録されているはず、と思ったのですが、ありません。むむ、手ごわいぞ。。。
ぼくが担当しているのは、PowerBuilderで作られたオンプレのクライアントサーバーアプリケーションです。実行個所を確認したら、以下のような記述が。。。
// タスクスケジューラのタスクを作成するバッチを実行する
run("addTask.bat")
およ。バッチファイルを実行している。これは、、、カレントディレクトリにあるバッチスクリプトを実行していますね。もしかして、カレントディレクトリが変更されたときには、動かなくなる、という可能性があるのでは。。。
普通にChangeDirectoryコマンドを使ってディレクトリを明示的に指定すれば当然カレントディレクトリを変更できます。それ以外にも、気づかないうちにディレクトリが変わっている可能性がありました。GetFileOpenName、GetFileSaveNameファンクションを使用した場合です。これらを使用するとダイアログウィンドウが開いてファイルを選択することができますが、選択したフォルダにカレントディレクトリが移動してしまいます。
VBAなどで開発されている場合には、GetOpenFilenameやGetSaveAsFilenameといったファンクションも同様の挙動で同じ問題が起きる可能性がありそうですよ!
と、いうことで、うまく動いたり動かなかったりするのは、おそらくこのカレントディレクトリの移動が原因じゃないかな、と、いう結論になりました。対応は、絶対パスでバッチファイルを記載するか、カレントディレクトリをバッチファイルのあるところへ変更してから実行するか、の、いずれかでしょうね。
今回調査が難しかったのは、普段あまり使用していなかったタスクスケジューラへの登録と実行、という難易度の高めの処理があったため、登録時の失敗や、実行時の失敗、ログオンしているときしていないとき、プログラム使用者の権限の問題などの可能性も考慮せねばならず、そちらへ大きく気を取られてしまった、ということがありました。
バッチファイルなどの外部スクリプトや他のプログラムがうまく動作しないことがあるときは、相対パスで指定されていないか確認しましょう。
あ、書いてて思いつきましたが、もしかしたらgetFolderファンクションでもカレントディレクトリが変わるかも知れません。。。
こんにちは。石川さんです。最近更新できていなかったので、中途半端ですが、最近の成果について記載します。AngularでKonvaを使ってTMのツールを作っているのですが、何やら警告が出ていたので、調べました!
「Warning: C:\……\xxx.component.ts depends on ‘konva’. CommonJS or AMD dependencies can cause optimization bailouts.」
なんか出ました。「ng serve」を実行すると、勝手にビルドが始まって、開発用のWebサーバーが起動するのですけど、ビルド終了時に上記のメッセージが出てまいりました。結構前から出てきていたように思うのですけど、まあこんなものなのかな、と、放置していました。ただ、システム開発をとことん極めます、と言っている人は、これを放置しちゃいけませんよねぇ、という気持ちになってきたので、調べます!
すぐ下に続きのメッセージが出ていましたので、まずはこちらを参照します。
「For more info see: https://angular.io/guide/build#configuring-commonjs-dependencies」
なるほど、AngularaはCommonJSに依存することをおすすめしてないのですね。最適化されなくて、サイズが小さくならなくなることがあるので、ECMAScript(ES)モジュールにした方がよい、ということだそうです。
なるほど、angular.jsonファイルの中の「build」オプションの「allowedCommonJsDependencies」に「konva」を追加すれば、警告は消せそうですね。ちょっとやってみます。
既に「”allowedCommonJsDependencies”: [“dialog-polyfill”],」となっていたので追加してみます。「”allowedCommonJsDependencies”: [“dialog-polyfill”,”konva”],」に変更して保存、「ng serve」実行中だったのでCtrl+cでいったん終了して、再度「ng serve」を実行してみます。
お、警告が消えましたね。
警告が消えましたが、本当はKonvaをESモジュールにした方がよいのでしょうね。と、いうことで調査しました。しかし、Konvaのバージョン8.0.0で、「Full migration to ES modules package (!), commonjs code is removed.」と、ESモジュール対応されているようでした。と、いうことは、よくわかりませんが、とりあえずは警告を消しておけば大丈夫、かな?
もっと突っ込んで調べようとしましたが、挫折しました。本来は、KonvaがESモジュールとして使えるはずなのに、Angularのビルダーが、CommonJSモジュールじゃないのかなぁ、と警告を出しているように思います。と、いうことでいったん終了です。
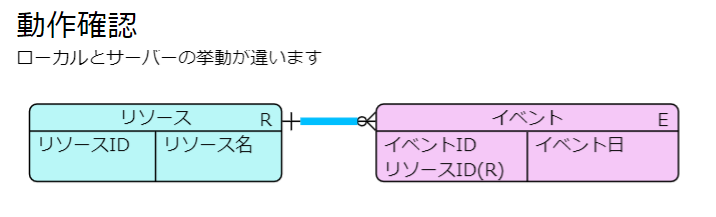
今日も見に来て下さってありがとうございます。石川さんです。ここのところTMのツール開発しているのですが、ローカルで作成したときに確認した挙動と、サーバーにデプロイしたプログラムの挙動が違っています。どうしてなのか、調べてみました。
結論を言うと、原因は突き止めて解決しましたが、理由までは分かりませんでしたよ。。。
まずは、ローカル側の挙動です。箱のデータはデータベースに書けるようになったので、線を引こうとまずは箱を探して、一つ目の箱から二つ目の箱へ1:Nのゼロありの線を引くようにしました。まだ作りかけなので、線は青いです。
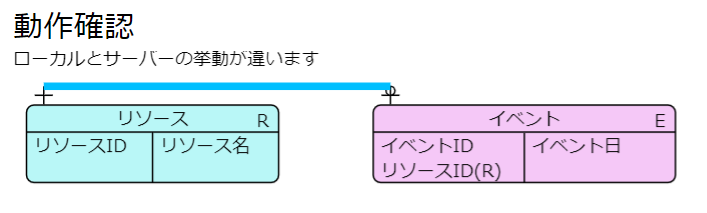
次に、サーバー側の挙動です。一つ目の箱は右のサイドから、二つ目の箱の左のサイドへ線を引く、という設定になっているはずなのですが、なぜか両方共の箱の上のサイドになってしまいます。プログラムはまったく同じ状態のはずなので、謎です。
そして、この接続点は移動できるように作っているので、サーバー側のプログラムで同じ位置になるように移動してみたところ、変な位置になってしまいました。なんてこったい。
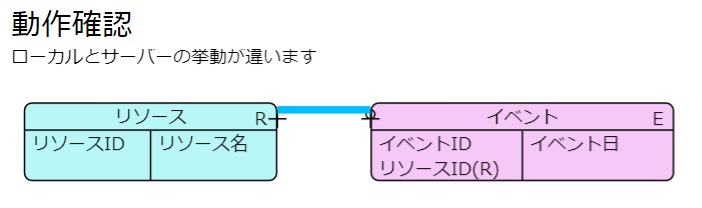
いやいや、これ解決できるのかなぁ。。。
Web開発の実務経験もセミナーなどで教わったこともなくて、すべて独学なので、こういうときに使える武器が全くないのですよね。ブラウザ(Chrome)にデバッガはついているのですけど、サーバー側にデプロイした状態だと、Typescriptのソースコードはjavascriptに変換されてしまっていて確認できなくなっているのですよね。と、いうことで、console.log()しか思いつきません。ま、あるものでやるしかないですよね。と、いうことで、まずは、Sideの情報と、1:NのときのNの情報がうまく処理できていないようですので、どうなっているのかログを出力してデプロイすることにします。
と、ソースコードを見始めましたが、使っているHTML5 Canvas JavaScript フレームワーク(KONVA)の使用方法が原因のようです。表示する図形、この場合は、接続点ですが、それぞれSideと1:Nの設定値のバリデータを手作りしていましたので、ログ出力する前に、ここのバリデータを使用しないように変更して、ビルド、デプロイしてみました。
すると、、、なんと、正しく動作しました!
ズバッと解決、、、は、しましたが、、、気持ち悪いですねぇ。
原因となった個所の、修正前のプログラムと修正後のプログラムを参考までに載せておきます。接続点の最大値を、Infinityにしたのですが、KONVAではInfinityは数値ではないようでバリデータがなかったため、KONVAのValidatorを参考にして、以下のように手作りしてみました。
-- 修正前(ローカルは動くが、サーバ側は正しく動かない)
Factory.addGetterSetter(TMConnectionPoint, 'maximum', "",
function(val:any,attr:any){
if (Konva.isUnminified) {
if (!(Util._isNumber(val) || val === Infinity)) {
Util.warn('[' + val.toString() + ']' +
' is a not valid value for "' +
attr +
'" attribute. The value should be a number or an Infinity.');
}
return val;
};
});
ビルドしてデプロイしたらローカルと挙動が変わってしまったので、KONVAのソースコードと同様となるように作り直しました。get~Validatorというファンクションをつくって、それをセットする、というやり方でしたのでそちらに習ってみました。違いとしては、Konva.isUnminifiedのフラグをチェックするタイミングです。タイミングの違いによって、挙動が変わったのかもしれません。JavaScript初心者なので、これ以上追っていくと時間がいくらあっても足りないので諦めます。(あ、AngularはTypeScriptでしたね。どっちにしても初心者でした。。。)上記のスクリプトではundefinedを戻していないよ、という、エラーは出ていなかったのですが、ファンクションを切り出したところでエラーが出てきたので追記しました。もしかしたらこの程度の些細な差、なのかも知れません。
-- 修正後(ローカルもサーバ側も正しく動作する)
function getNumberOrInfinityValidator(){
if (Konva.isUnminified) {
return function(val:any,attr:any){
if (!(Util._isNumber(val) || val === Infinity)) {
Util.warn('[' + val.toString() + ']' +
' is a not valid value for "' +
attr +
'" attribute. The value should be a number or an Infinity.');
}
return val;
};
}
return undefined
}
Factory.addGetterSetter(TMConnectionPoint, 'maximum',"", getNumberOrInfinityValidator());
Web開発では、ローカルでうまくいったからと言って、サーバにデプロイしてもうまく動くとは限らない、ということを知りました。そして、そのような事態になったときは、とても心細いですね。
こんにちは。石川さんです。
KONVAを使ってTMのお絵かきツールを作っています。しかし、イベントの処理順序がよく分からなくなってきましたので、実際のスクリプトで検証してみることにします。せっかくなので、皆さんにも結果を公開します!(必要なひと、滅多にいないと思いますが!(笑))
KONVAのチュートリアルサイトの中にあるイベントに関する記事からイベントを抜き出しました。(左側に「EVENTS」と書いてあるところにある記事です。)そして、それぞれのオブジェクト毎にどのような順番で実行されるのか、出力するようにしてみます。
先日お試しでjavascriptを組み込んでみましたが、今回もそれで試してみます!
赤い丸はドラッグ可能です。いろんなイベントを試してみてください。
<script src="https://unpkg.com/konva@9.2.0/konva.min.js"></script>
<div id="container20230724"></div>
<script>
function writeMessage(message) {
let lines = text.text().split("\n");
lines.splice(0, lines.length - 10);
if(lines[lines.length - 1].indexOf(message) == -1) {
lines.push(message);
} else {
lines[lines.length - 1] = lines[lines.length - 1] + "."
}
text.text(lines.join("\n"));
}
var stage = new Konva.Stage({
container: 'container20230724',
width: window.innerWidth,
height: 500/*window.innerHeight*/,
});
var layer = new Konva.Layer();
var text = new Konva.Text({
x: 10,
y: 200,
fontFamily: 'Calibri',
fontSize: 24,
text: '',
fill: 'black',
});
var triangle = new Konva.RegularPolygon({
x: 280,
y: 120,
sides: 3,
radius: 80,
fill: '#00D2FF',
stroke: 'black',
strokeWidth: 4,
draggable: false,
});
var circle = new Konva.Circle({
x: 430,
y: 100,
radius: 60,
fill: 'red',
stroke: 'black',
strokeWidth: 4,
draggable: true,
});
const KEVENTS = [{
eventName:'MouseEvents',
event:['mouseover','mouseout','mouseenter','mouseleave','mousemove',
'mousedown','mouseup','wheel','click','dblclick',]
},{
eventName:'TouchEvents',
event:['touchstart','touchmove','touchend','tap','dbltap',],
},{
eventName:'PointerEvents',
event:['pointerdown','pointermove','pointereup','pointercancel','pointerover',
'pointerenter','pointerout','pointerleave','pointerclick','pointerdblclick',],
},{
eventName:'DragEvents',
event:['dragstart','dragmove','dragend',],
},{
eventName:'TransferEvent',
event:['transformstart','transform','transformend',],
}
]
for(const e1 of KEVENTS) {
for(const e2 of e1.event){
stage.on(e2, (event) => { writeMessage(e1.eventName + " Stage " + e2); })
triangle.on(e2, (event) => { writeMessage(e1.eventName + " Triangle " + e2); });
circle.on(e2, (event) => { writeMessage(e1.eventName + " Circle " + e2); });
}
}
layer.add(text);
layer.add(triangle);
layer.add(circle);
// add the layer to the stage
stage.add(layer);
</script>
ステージと三角と丸とテキストをつくって、テキスト以外のそれぞれにイベントを登録しました。テキストはイベント内容の出力用です。丸はドラッグ可能、▲はドラッグ不可能にセットして、それぞれイベントが発生したときに、発生したイベントをテキストに出力するようにしてみました。
イベント、たくさんありますね!たくさんありすぎて、動かしていくと訳が分かりません。そのうち、イベントをオフにする機能も追加してわかりやすくしたいと思います。→と、思って色々とやってみましたが、HTML要素をプログラムで追加するとうまく表示を制御できなかったので、いったん諦めます。
こんにちは。石川さんです。実現するのに調べても答えがなかったので、書いておきます。きっと誰かのお役に立てると思います。
外部連携用のCSVデータファイルを作成するのに、相手先がUTF-8でなければならない、ということでした。PowerBuilderのアプリケーションはUTF-8の場合、BOM付きでないとエラーになってしまうので、すべてBOM付きに統一しましょう、となりました。PowerBuilderのアプリケーションはそれで問題なし、となりましたが、SQL*Plusからの出力はBOMなしでしか出力できず。UTF-8にするのは「NLS_LANG=.UTF8」を指定して実行するだけでできたので、簡単に終わると思ったのですけどねぇ。。。と、いうことでSQL*PlusからUTF-8のBOM付きで出力する方法です。
お急ぎの方に簡単に言うと、スクリプト実行時に、事前用意したBOM付きのファイルをコピーしてきて、そこにAPPENDでスプールする、ということだけです。BOM付のファイルってなんなのって、ファイルの先頭に決まった3バイトが入っているかどうか、ということなので、そのファイルを用意して続きを埋めていくようにしておけば、BOM付ファイルの出来上がり、というわけです。
BOM付きUTF-8のヘッダファイルを用意します。ぼくはサクラエディタを使って用意しました。文字コードセットに「UTF-8」を選んで「BOM」にチェックをつけるだけです。
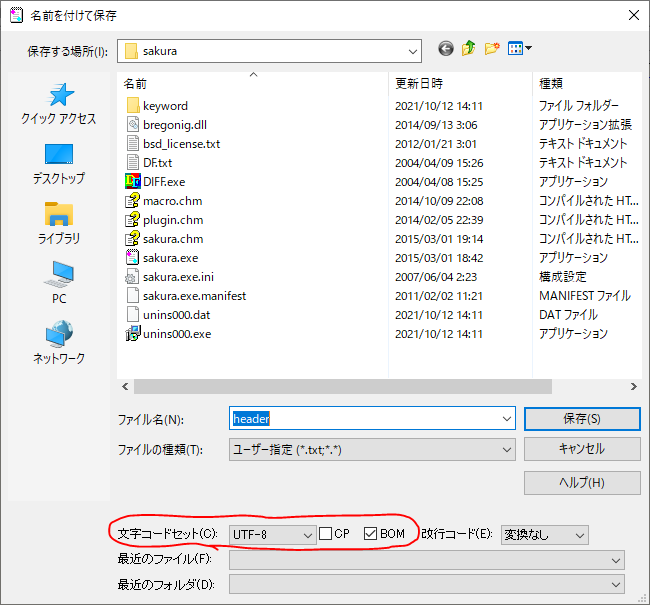
これでBOM付きのファイルができました。今回ファイル名は「header.txt」としました。
SQL*Plusへ読み込ませるスクリプトファイルを作成します。以下はサンプルです。
WHENEVER SQLERROR EXIT FAILURE
WHENEVER OSERROR EXIT 50
set termout off
set head off
set pagesize 0
set linesize 2000
set trimspool on
set timing off
set time off
set feedback off
set echo off
-- このスクリプトは環境変数に「NLS_LANG=.UTF8」をセットして実行すること。
-- BOM付きUTF8のファイルにするため、スプール(APPEND)を開始するまえに、BOM付きのヘッダ情報ファイルをshohin.csvとして作成しておくこと。
host copy header.txt shohin.csv
spool shohin.csv APPEND
SELECT T1.商品コード||','||
T1.商品名||','||
T1.商品価格
FROM 商品マスタ T1
WHERE T1.送信対象 = 1
ORDER BY T1.商品コード
;
spool off
exit 0
このスクリプトの最初のポイントは、「host copy header.txt shohin.csv」のところです。スプールする直前に、ファイルをコピーしています。「host」はWindowsのコマンドを使います、というコマンドで、COPYコマンドを使って単にファイルをコピーしています。(ぼくの実行環境はWindowsサーバーです。Linuxだとcpとかになると思います。)
第二のポイントは、スプールコマンド(spool)の最後に書いた「APPEND」です。これが記載されることによって、追記されるようになります。「APPEND」を指定しない場合は、デフォルトで「REPLACE」が指定されたことになり、ファイルが存在する場合は上書きされてしまいます。そうすると、せっかくコピーしたBOMが消えてしまいますので、注意が必要です。
最後に入手したいデータを取り出すSQL文を書いて、「spool off」します。これで完了です。
上記のサンプルを「targetscript.sql」ファイルに保存したとして、以下のようなコマンドで実行します。これで、ファイルを現在のディレクトリに作成してくれます。実際にはスケジューラーにこのコマンドを環境変数付きで実行したので、もし環境変数が正しく機能しない場合は、ご容赦ください。
set NLS_LANG=.UTF8 sqlplus username/password@connectstring @targetscript.sql
SQL*PlusでBOM付きのUTF8ファイルへスプールするためには、最初にBOM付ファイルをコピーしてきて、APPENDでSPOOLするのがよいでしょう。
こんにちは、石川さんです。開発中のPowerBuilderのアプリケーションからWinSCPを使って通信する方法を調べたのですが、ちょっと難しかったので記録しておきます。誰かのお役に立ちますように。実行環境は64ビット版のWindows 10で、PowerBuilder 2017 R3の32ビットアプリケーションを開発しています。
階層化したフォルダーへファイルを展開する必要があったので、複雑なことができるよう.NetアセンブリをOLEオブジェクトとして利用できる方法についてのお話になります。単なるEXEとして実行する方法ではありません。
英語が読める方は、こちらを読むようにお願いします。手順としては、
です。
まずは、ダウンロードします。こちらのページにありました。PowerBuilderからの利用には、「.NET assembly / COM library」を選択すれば使えるようです。以下のリンクをクリックしてファイルをダウンロードします。
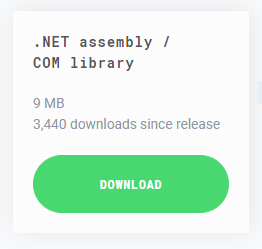
ダウンロードされるファイルは「WinSCP-X.X.X-Automation.zip」のような名前になっています。ぼくがダウンロードしたときは、「WinSCP-5.21.7-Automation.zip」でした。
zipファイルを解凍した中にある、「WinSCPnet.dll」が本体、「WinSCP.exe」が実行形式のファイルだそうです。dllを確認したところ、32ビット版でした。開発中のアプリケーションが32ビット版なので、ここは一致している必要があるような気がします。ぼくの環境ではこの二つのファイルを展開するだけで使えるようになりました。
次にOLEオブジェクトとして利用できるようにする手順ですが、以下のコマンドを実行します。WinSCPnet.dllのあるフォルダで実行ですよ!実行するとレジストリに登録されるようです。レジストリの中まではざっとしか確認していません。
%WINDIR%\Microsoft.NET\Framework\<version>\RegAsm.exe WinSCPnet.dll /codebase /tlb REM ぼくの環境では以下のとおりでした。 C:\Windows\Microsoft.NET\Framework\v4.0.30319\RegAsm.exe WinSCPnet.dll /codebase /tlb
これで、使えるようになりました。あとは、PowerBuilderでコーディングするだけですね。ちなみに、実行すると「WinSCPnet.tlb」というファイルができました。登録を解除するには「/tlb」ではなく「/unregister」を指定して実行すればオッケーのようです。このあたり、あまり詳しくありません。試しに「/unregister」を指定したコマンドを実行してから開発中のプログラムを実行したらエラーがでていました。
ここのソースコードをコピペして動かしてみました。ただし、そのままだと動かなかったので、少し変更しました。変更部分を含めて再登録しておきます。ボタンをつくって、クリックしたときのイベント(clicked)に記載して確認しています。
oleobject s_ftp // for WinSCP.Session
oleobject s_opt // for WinSCP.SessionOptions
oleobject s_trans // for WinSCP.TransferOptions, i just used default values (Binary transfer and overwrite options)
int return_code
s_ftp = CREATE oleobject
return_code = s_ftp.connectToNewObject("WinSCP.Session")
if return_code <> 0 then
messagebox("Error", "S_FTP Component installation error")
return - 1
end if
s_opt = CREATE oleobject
return_code = s_opt.connectToNewObject("WinSCP.SessionOptions")
if return_code <> 0 then
messagebox("Error", "Seasion Options Component installation error")
return - 1
end if
s_trans = CREATE oleobject
return_code = s_trans.connectToNewObject("WinSCP.TransferOptions")
if return_code <> 0 then
messagebox("Error", "Transfer Options Component installation error")
return - 1
end if
s_opt.protocol = 2 // 0:SFTP 1:SCP 2:FTP WEBDAV:3
s_opt.hostname = "CHANGE YOUR IP" // server IP
s_opt.UserName = "CHANGE YOUR ID" // user id
s_opt.Password = "CHANGE YOUR PASSWORD" // user pass
//s_opt.GiveUpSecurityAndAcceptAnySshHostKey = true // this is not save, instead server key should be used
//s_opt.SshHostKeyFingerprint = "ssh-rsa 2048 xxxxxxxxxxx..."
try
any result
result = s_ftp.open(s_opt)
// return integer(result) ←これがあって、下のputfilesが実行できなかったのでコメントアウト
catch (runtimeerror e)
messagebox("Error",e.getMessage())
return -1
end try
Ll_rtn = integer (s_ftp.putfiles("C:\poi.txt", "/FTP/poi.txt", false,s_trans ) ) // ローカルからリモートへコピー
IF Ll_rtn < 0 THEN
as_msg = "File Upload Error(FTP)!"
END IF
s_ftp.close()
以上です!このあとに続く、これ以上の開発にはこちらのライブラリの情報が必要です。
皆さんの環境でもうまいこと動きますように。
実際に開発を進めていって、s_ftp.putfiles()の戻り値がうまく取得できていないことが発覚しました。これではエラーハンドリングできません。と、いうことで、後半をちょっと追記しますと、、、こんな感じに仕上がりました。
OLEObject s_result // for WinSCP.TransferOperationResult //ファイル送信 s_result = s_ftp.putfiles(as_fileName, ls_folder, false, s_trans ) if s_result.isSuccess then s_ftp.close() return "" else s_result.Check() end if catch (oleRuntimeError oe) destroy s_trans destroy s_opt destroy s_ftp return "WinSCPの処理に失敗しました。~n~n【詳細】~n"+oe.Description+"~n~n"+oe.getMessage()+")" catch (runtimeerror e) destroy s_trans destroy s_opt destroy s_ftp return "WinSCPの処理に失敗しました。(エラーメッセージ:"+e.getMessage()+")" end try
戻り値を取得するためのOLEObject変数s_resultを設定し、s_result.isSuccessをチェックすることで成功か失敗か、ということが判断できます。失敗したときは、s_result.Check()を呼び出すことでOLEランタイムエラーを発生してくれます。このs_result.isSuccessだけでも充分だと思いますが、一箇所でハンドリングしたいときなどは、いきなりs_result.Check()を呼び出すとよいと思います。
こんにちは。石川さんです。ChatGPT、何でも答えてくれるので、仕事のお悩みを聞いてもらいました。
事の発端は、今開発中のシステムでのお話です。連携用のデータの中にカンマがありまして、そのままCSVデータとして送信すると、エラーになってしまいました。ま、CSVはカンマ区切りの値ですから、カンマは何らかの処置をしてあげなければいけません。ぼくとしてはデータを「”」ダブルクォーテーションでくくるのがお好みなのですが、要望は半角カンマは全角に置き換えてください、ということでした。ORACLEからSQLを使ってデータを取出していましたので、このSQLを変更するのが楽でよさそうですね。そこで、TRANSLATEを使って置き換えることに決めました。イメージはこんな感じになります。
-- 修正前 SELECT 商品コード||','||商品名||','||単価 FROM 商品マスタ; -- 修正後(TRANSLATEを使って半角カンマ「,」を全角カンマ「,」に置き換える) SELECT 商品コード||','||TRANSLATE(商品名,',',',')||','||単価 FROM 商品マスタ;
そう、色々と調べて、これでうまくいくね、というときに閃きました。ChatGPTに聞いてみたら、ちゃんと教えてくれるのでしょうか。気になって聞いてみました。
そうするとですねぇ、ぼくが調べたTRANSLATEではく、REPLACEをおすすめしてきました。なるほど。この場合は、書き方の違いは関数名だけですね。
-- おすすめ結果
SELECT REPLACE('1,2,3,4', ',', ',') FROM dual;
そこで、次の質問です。
そうすると、関数の違いを説明してくれて、利点を述べてくれました。その上で何と、置換対象が一つしかない場合はREPLACEの方が単純で実行速度が速くなる、と、教えてくれました。ご存知だと思いますがTRANSLATEは指定された文字列中の文字を対応させて変換してくれます。REPLACEは指定された単語を指定した単語へ変換してくれます。なので、それは本当のような気がしましたが、置換する文字が増えるなどの拡張性を考えた場合、TRANSLATEの方がいいような気がしたので、更に質問を続けます。
この質問に対する回答では、拡張があるならTRANSLATE使ってね、と言ってもらいました。ただ、先程の質問を繰り返したような感じだったせいか、同じような回答でした。さらに、具体的にどれくらい速いのか知りたくなって聞いてみました。
こんな無茶ぶりでもちゃんと答えてくれました。テーブルを作ってランダムなデータを1万件投入してUPDATEで更新した様子と、その実測した結果を示してきました。ワオ!
TRANSLATE関数を使用した場合: 2.9秒REPLACE関数を使用した場合: 0.6秒いや~、これはすごいですね!ちょっと感動しました。お礼を述べて一旦終了したのですけど、、、そんなに違うかなぁ、、と思い、自分でも実測してみることにしました。1万件のデータを作って、半角の3を全角の3に置き換えて、3333を取り出す、というのを実験してみました!
-- まずはTRANSLATE
with s(n) as (
select 1 n from dual
union all
select n + 1 from s where s.n < 10000
)
select * from s
where translate(to_char(n),'3','3') = '3333';
-- 次にREPLACE
with s(n) as (
select 1 n from dual
union all
select n + 1 from s where s.n < 10000
)
select * from s
where replace(to_char(n),'3','3') = '3333';
--【実測します!】--
SQL> with s(n) as (
2 select 1 n from dual
3 union all
4 select n + 1 from s where s.n < 10000
5 )
6 select * from s
7 where translate(to_char(n),'3','3') = '3333';
N
----------
3333
経過: 00:00:00.15
SQL> with s(n) as (
2 select 1 n from dual
3 union all
4 select n + 1 from s where s.n < 10000
5 )
6 select * from s
7 where replace(to_char(n),'3','3') = '3333';
N
----------
3333
経過: 00:00:00.15
SQL>
結果が出ました。どちらも0.15秒です!やはり、2.9秒は怪しいと思いました。(笑)
1回目より2回目の方の実行速度が速くなるのはOracleがバッファキャッシュを利用しているのでよくある話なのかも、と、いうことで、再度質問してみました。
そうすると、少々時間が経ってから「申し訳ありませんが、私の前回の回答に誤りがありました。実際には、TRANSLATE関数の方がREPLACE関数よりも実行速度が速いことが多いです。私の回答が混乱を招いてしまったこと、お詫び申し上げます。」と素直に間違いを認められました。で、ちょっと追加説明してから「再度、前回の回答が誤りであったことをお詫び申し上げます。」ですって。丁寧過ぎでしょ!
いや、感動しました。ChatGPT、すごいね!!!
こんにちは、石川さんです。
最近、思うところがあって、JavaScriptの勉強を始めました。今読んでいるのは、そう「初めてのJavaScript 第3版」です。Angularを使い始めたので本来はTypeScriptの勉強、と言いたいところですが、一冊本を読んで、先にJavaScriptだな、という気持ちになったのでした。
いや~、JavaScript、思っていたよりも、色々とできるのですねぇ。テンプレートリテラルとか、クロージャとか、完全にPythonだけのものだと思っていたのですけど、いや、視野が狭かったですね!反省しました。
せっかく勉強しているので、色々と披露したいよねぇ、という気持ちになってきたところで気になりました。そういえばWordPressのこのページ、JavaScriptを使用できるのでしょうか。先日調べたところ、ブロックを選択すればできる、ということがどこかに書かれていましたので、ちょっと試してみましょう。
まずは、ブロックを追加します。「カスタムHTML」が選べるので、こちらを選択します。
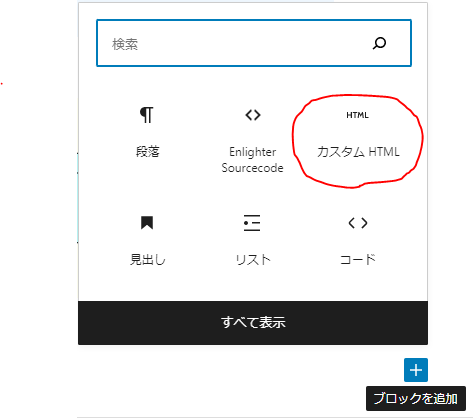
すると、以下のように「HTMLを入力…」となりますので、ここへスクリプトを記載して行きます。「プレビュー」を押すと実行結果のプレビューが表示されます。
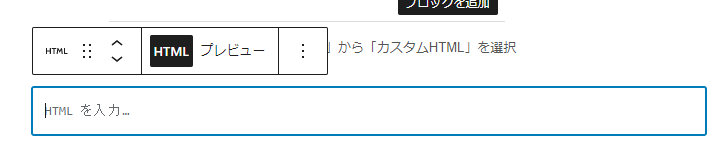
入力して保存したところ、簡単にできました!
【1つ目】
【2つ目】
できましたね!
簡単でした♪
今回入力したスクリプトは以下の通りです。
まずは【1つ目】です。ほぼこちらのスクリプトをコピペしたものです。Konva.jsという、HTML5 2d canvasのためのJavascriptライブラリを紹介しているホームページです。
HTML要素のidがページ全体にかかわってくるので、idは、container20230303_1に変更しました。(すみません、後で気づきました。調子にのって、他の記事でもcontainerを使ったところ、一覧で見たときにかぶって変なことになってしまいました。。。)
次に【2つ目】のスクリプトです。
<style>
div#container20230303_2 {
height: 200px;
width: 116%;
background-color: ivory;
}
</style>
<div id="container20230303_2"></div>
<script src="https://unpkg.com/konva@8/konva.min.js"></script>
<script>
var height = 200;
var width = window.innerWidth;
var resourceColor = 'rgb(185, 247, 247)';
var eventColor = 'rgb(245, 200, 247)';
var stage = new Konva.Stage({container: 'container20230303_2', width: width, height: height, draggable:true});
stage.on('contextmenu', function (e) {
e.evt.preventDefault();
});
var layer = new Konva.Layer();
stage.add(layer);
function newBox(title, type) {
return new Konva.Rect({
cornerRadius: 10,
fill: type === "resource" ? resourceColor : eventColor,
stroke: 'black',
strokeWidth: 1,
name: 'rect',
draggable: true,
sceneFunc: function (context, shape) {
shape._sceneFunc(context);
context.beginPath();
context.moveTo(0,20);
context.lineTo(shape.getAttr('width'),20);
context.moveTo(shape.getAttr('width')/2,20);
context.lineTo(shape.getAttr('width')/2,shape.getAttr('height'));
context.stroke();
context.closePath();
context.font = '12px sans-serif';
context.fillStyle = "rgb(0, 0, 0)"
context.fillText(title,25,17);
}
});
};
var rect1 = newBox("リソース", "resource");
rect1.setAttrs({x: 60, y: 60, width: 100, height: 90});
layer.add(rect1);
var rect2 = newBox("イベント", "event");
rect2.setAttrs({x: 260, y: 60, width: 100, height: 90});
layer.add(rect2);
rect2.on('click', (event) => {console.log('clicked!', event);});
</script>
簡単に色々なことができるので、夢が広がりますね!