このホームページはWordPressで構築したのですけど、お問い合わせフォームのプラグインにはContact Form 7を使わせていただきました。開設したばかりのホームページなのに、このお問い合わせフォーム経由で海外からの英文メールが届くようになってしまいましたので、reCAPTCHA v3でBot対策することにしました。
2月10日にお問い合わせフォームを設置、3月19日に初お問い合わせ受信、その10日後に2通目のお問い合わせ受信、4月に入ってからもチラホラ来るようになったので、ムダだと思いつつもフォームに(Japanese only)を付けてみました。Botではなくて、本当に人が入力していたら無視するのも申し訳ないなぁ、と、思いまして。ま、予想通り効果なく、すべて英文でのメールで4月は結局7通受け取ることになりました。お問い合わせが一通も来ないよりかはいいかな、とも思いましたが、このまま増え続けるとやだなぁ、ということで今までぐずぐずしていたのですけど、ゴールデンウィークということもあり、本日設定に踏み切りました。
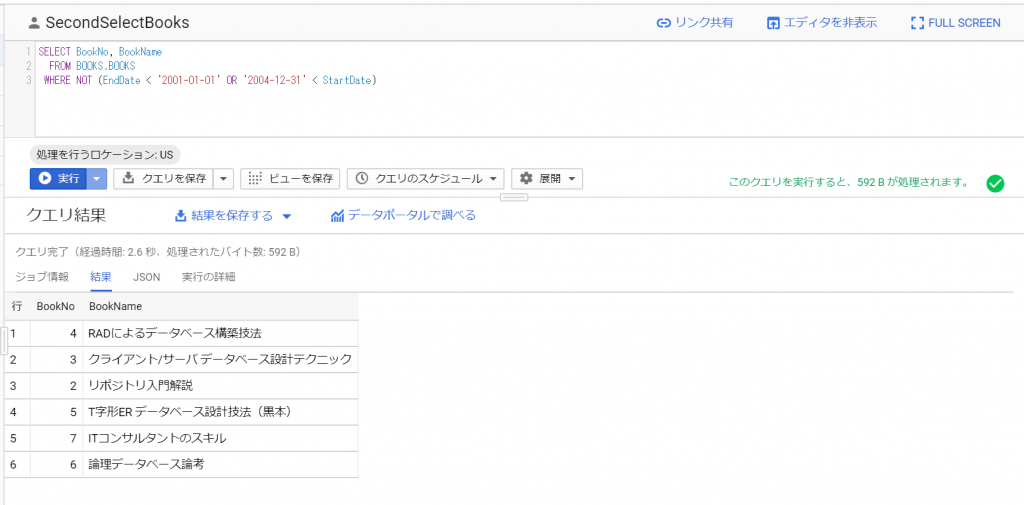
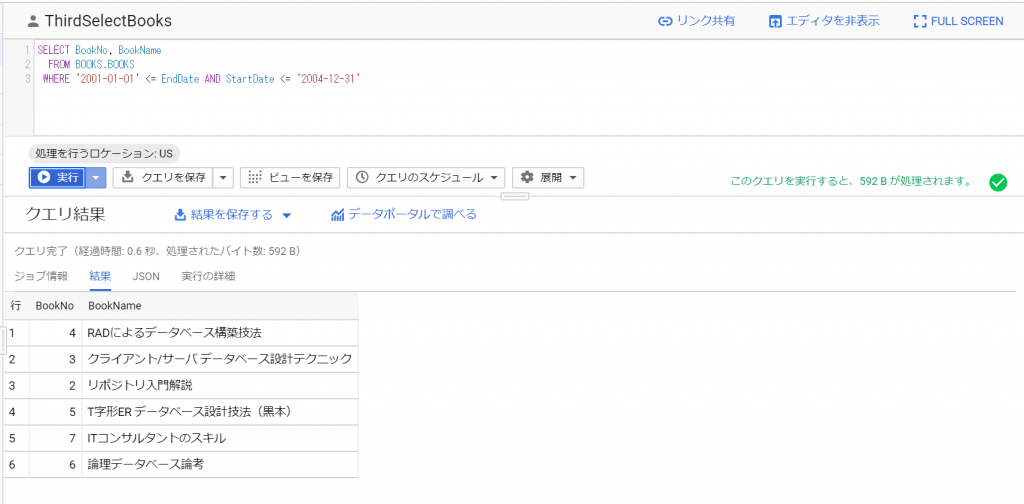
Contact Form 7の説明のスパム対策として「賢いreCAPTCHAはうっとおしいスパムボットをブロックしてくれます。」と書いてあったので、やってみるか、という単純な動機です。このreCAPTCHAを入れたら、例の「私はボットではありません」のチェックボックスとか、波打ったアルファベットの画像を入力させるメニューが追加されるのでしょうか。と、いうことでさっそく設定してみます。お問い合わせメニューのインテグレーションを選択したら、以下の通り。reCAPTCHAインテグレーションモジュールを使えば、スパムボットによる不正なフォーム送信が遮断できるそうです。
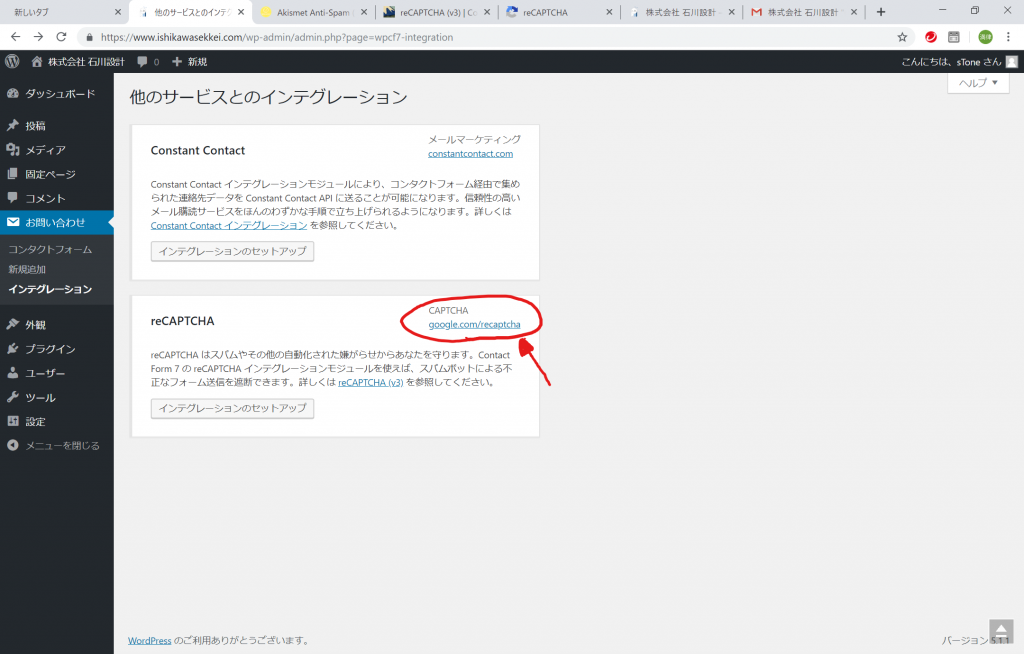
まずは、グーグルさまの設定が必要ということで、「google.com/recaptcha」へ行ってみます。reCAPTCHAってグーグルさまのサービスなのですね。
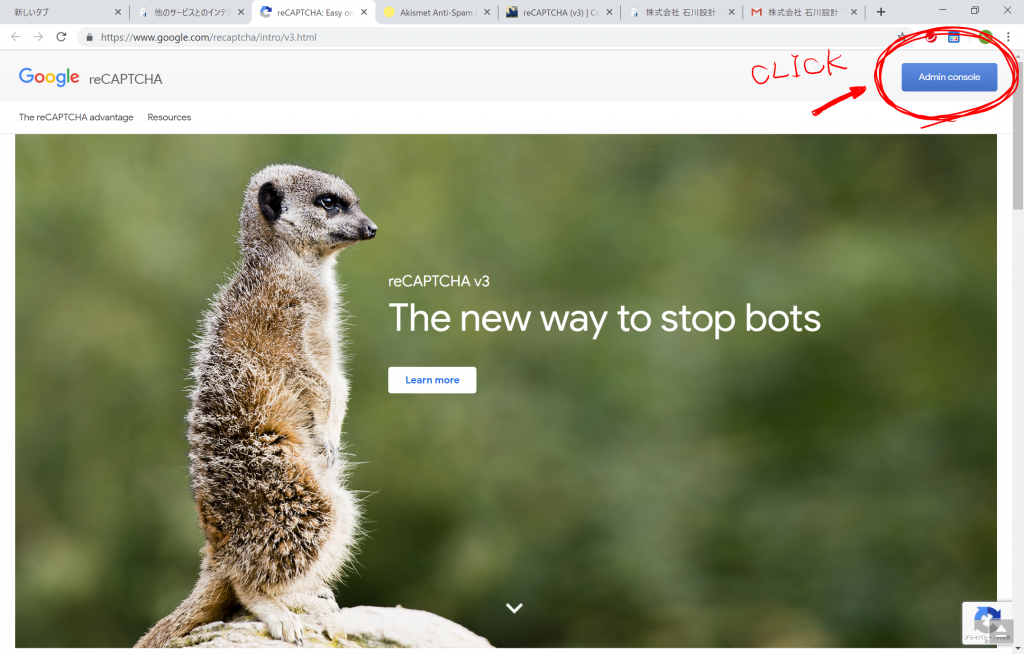
Admin consoleをクリックすると以下のように新しいサイトを登録する画面が表示されました。Chromeにログインしていなければ、ログインを促されるかもしれません。ラベルに適当な名前を入力、reCAPTCHAはv3を選択、ドメインはこのサイトのドメインを入力しました。オーナーはログインに使用しているメールアドレスが表示されていました。reCAPTCHA利用条件に同意する、にチェックを入れて、
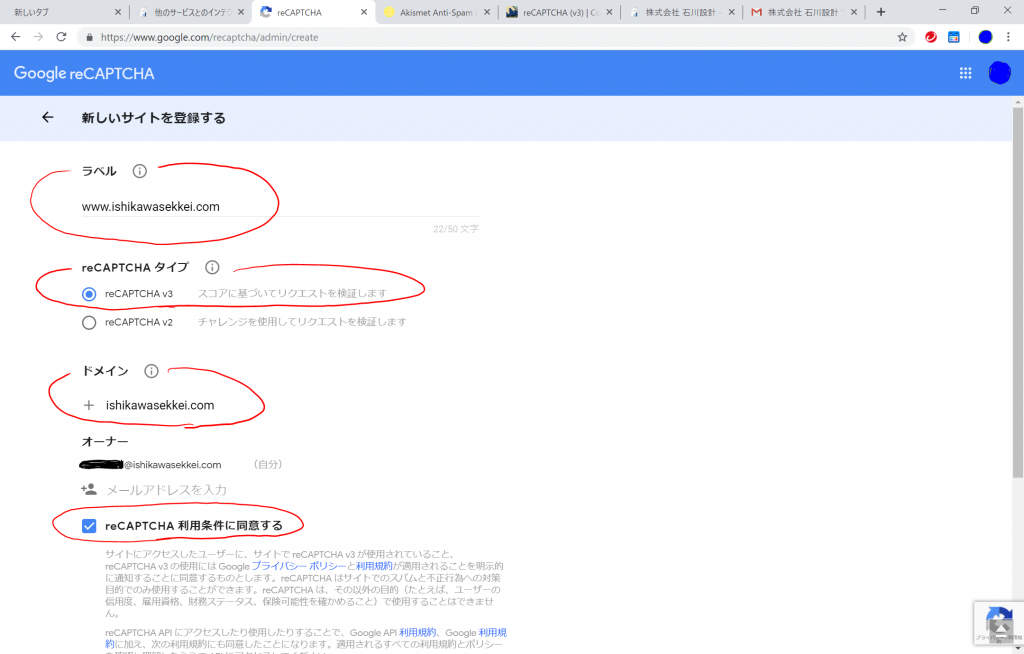
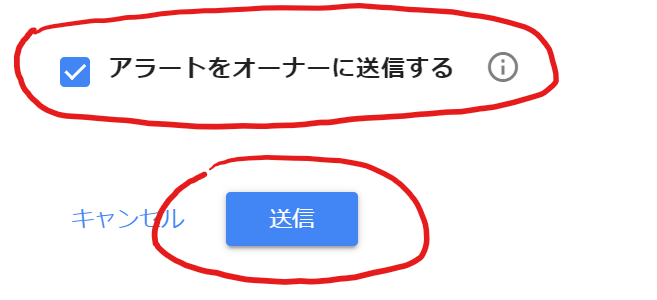
アラートをオーナーに送信する、は、初期値のチェックされたまま、「送信」ボタンをクリックしました。
すると、登録されました、ということで、サイトキーとシークレットキーが作成されました。
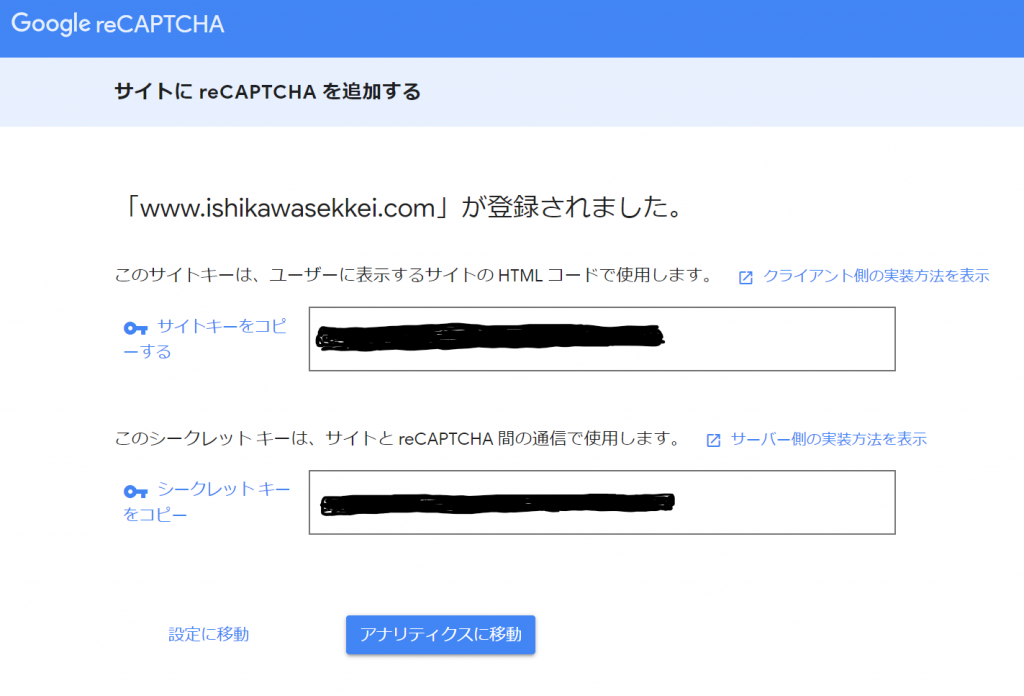
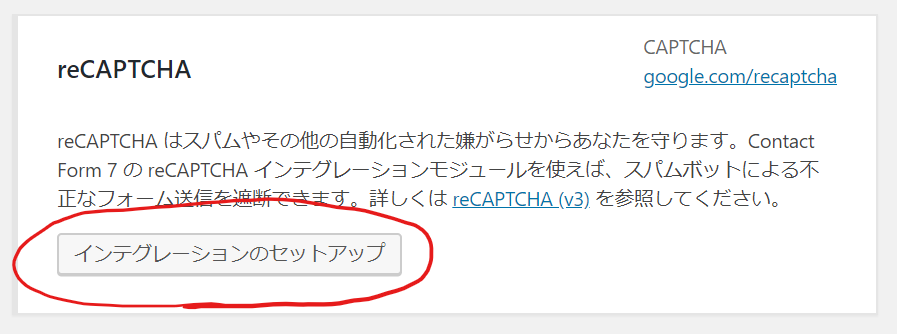
次は、お問い合わせの方へ戻って「インテグレーションのセットアップ」をクリックします。
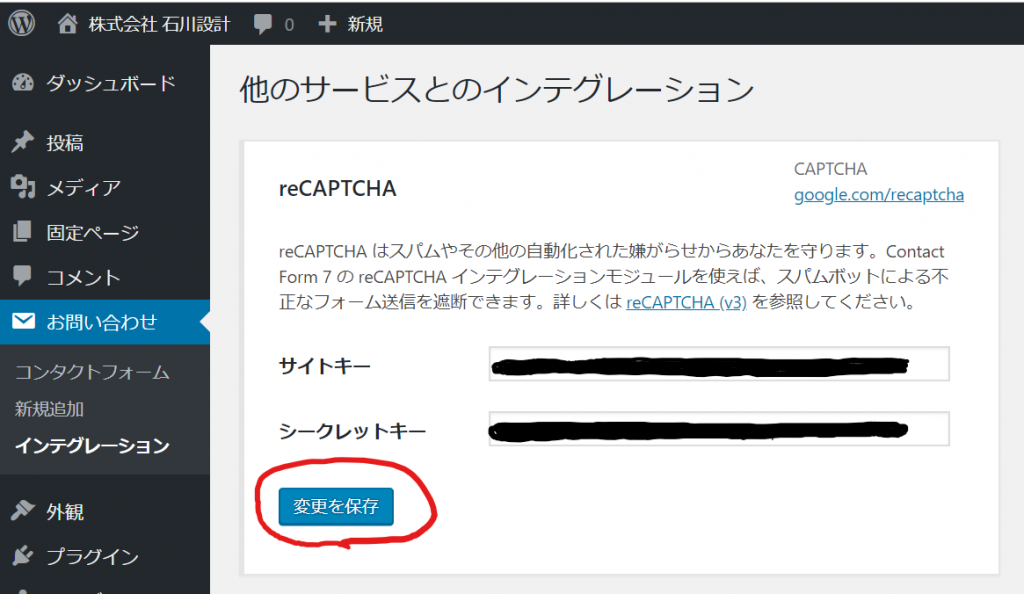
表示された画面に、サイトキーとシークレットキーを入力して、「変更を保存」ボタンをクリック。
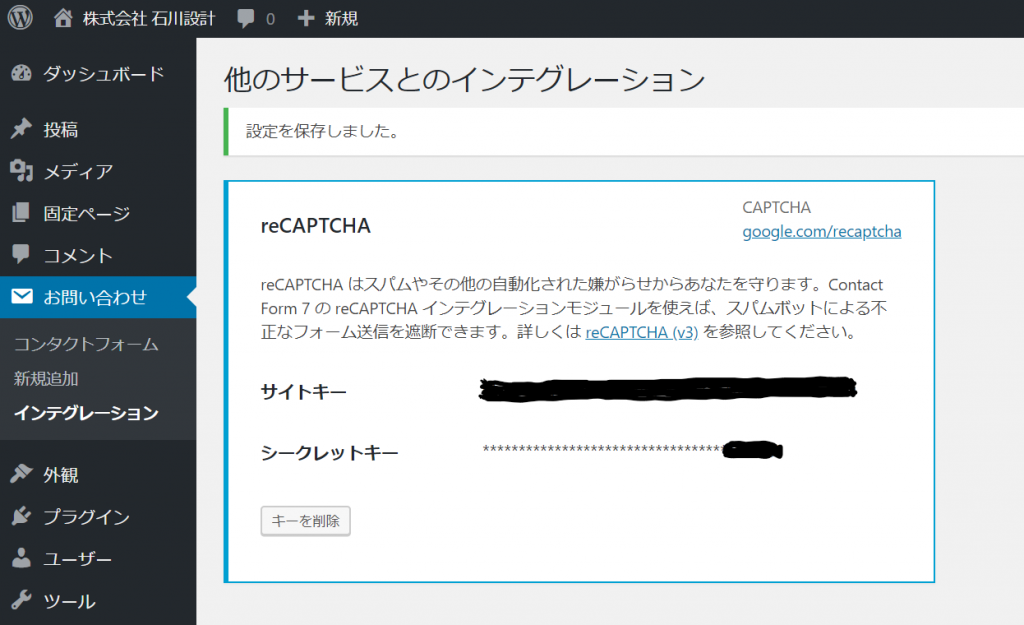
設定は以上で完了です。なんだかあっけないなぁ。ホントにこれでできたのでしょうか。
と、いうことで、確認してみます。画面の右下にreCAPTCHAのアイコンが表示されるようになりました。これで完了、ですよね?
どうやらチェックボックスでの確認はv2までで、v3は入力したときのリクエストにユーザからの摩擦(fliction)によって、スコアを付けて判定しているようですね。さすが、グーグルさまのサービス、凡人では思いつかないサービスですね。と、いうことで、これでしばらく様子を見てみることにします。
ちなみに、このグーグルさまのサービス、トラフィックデータがたまってきたら、リクエスト数、スコア分布、上位10件のアクション、不審なトラフィックのアクション(上位10件)なのでグラフが見られるようになるようです。データがたまってくるのが楽しみです。