
前回のエントリーの続きです。やっとGoogle Cloud SDKがインストールできたところまで書きました。bq コマンドライン ツールの使用に関するクイックスタートに書いてありましたが、インストールした後にはBigQuery APIを有効にする必要があるそうです。

「APIを有効にする」ボタンをクリックしてみます。
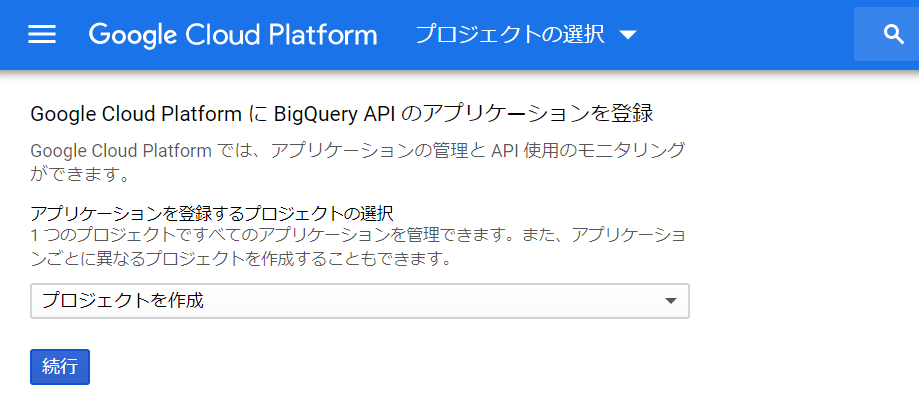
上記のGCPのページへ遷移しました。プロジェクトを選ぶ必要があるようです。
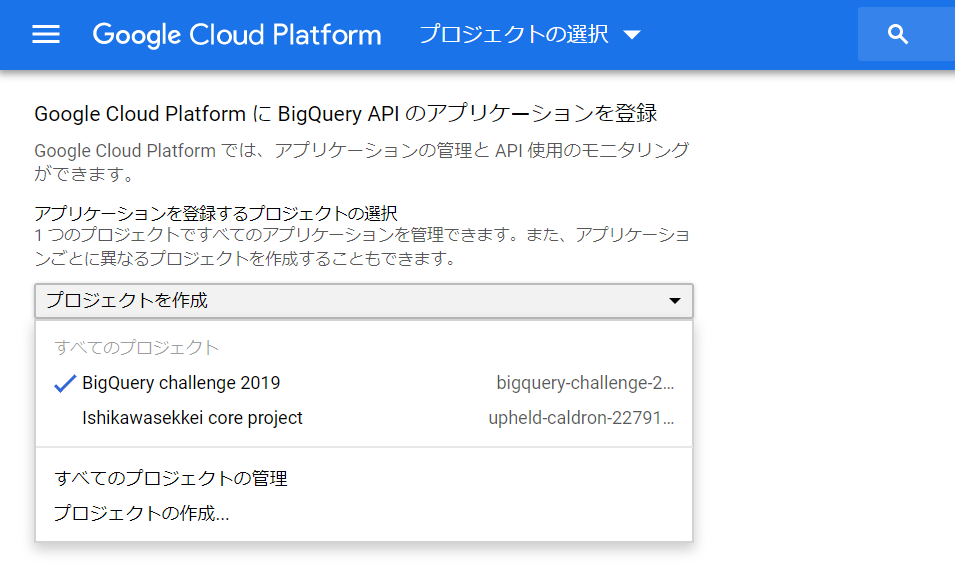
BigQuery APIはプロジェクトごとに設定するようですね。アプリケーションごとに設定することもあるのでしょうか。こちらは不明ですねぇ。とりあえず今回のために作ったプロジェクト(BigQuery challenge 2019)を選択して、「続行」ボタンをクリックします。左下に「APIを有効にしています」というポップアップがでて、次のような表示にかわりました。
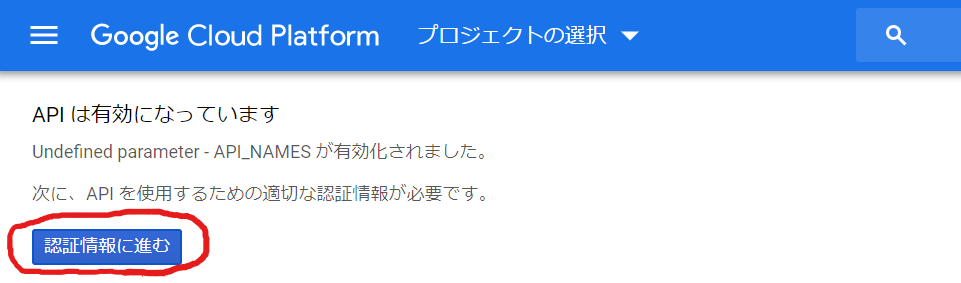
なるほど、APIは有効でしたか。次は、適切な認証情報ということで、「認証情報に進む」ボタンをクリックしてみます。
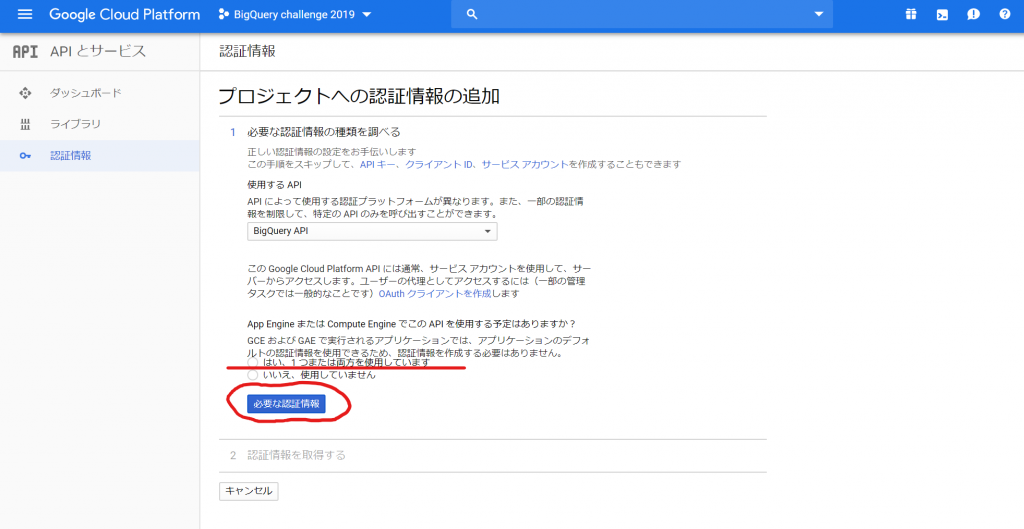
おお~、これはなんだか難しそうですねぇ。あ、でも、お手伝いしていただけるようです。使用するAPIは、「BigQuery API」がセットされているので、これで問題ないでしょうね。App EngineまたはCompute EngineでこのAPIを使用する予定、あるのかなぁ。。。将来的には、App Engineでアプリケーションを作って、BigQueryのデータを呼び出して使いたいから、「はい、1つまたは両方を使用しています」を選択すべきか、今回のテーマはあくまでローカルファイルをアップロードすることだから、「いいえ、使用していません」を選ぶべきか、悩むなぁ。お、よく読むと、App Engineでは必要ない、と、書いてあるような気がするなぁ。と、いうことで「いいえ、使用していません」を選ぼう。そして、「必要な認証譲歩」ボタンをクリックします。
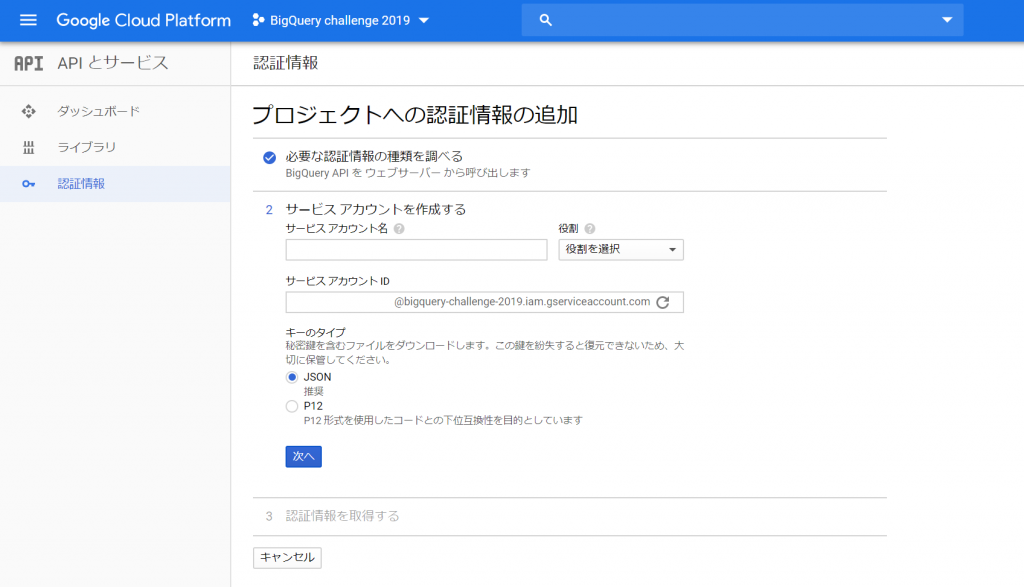
画面が変わって、次は、「サービスアカウントを作成する」必要があるようです。サービスアカウント名は、自由でいいのかな?「?」をポイントすると「このサービスアカウントで行うことを説明します」と、ヒントがポップアップしました。役割は、おお、意外といっぱいありました!
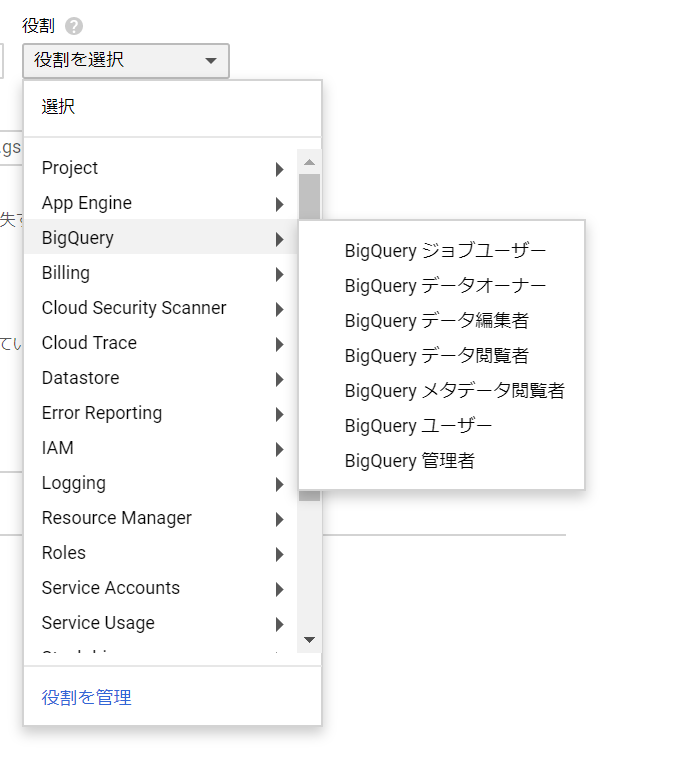
今回は、テーブル定義が作られた状態からのデータを投入する、ということで考えているので、「BigQuery データー編集者」が適切なのかな。「BigQuery ユーザー」とはどう違うのでしょうか。。。わかりませんが、とりあえず選択して進めましょう。 では、サービスアカウント名を「サンプルデータをロードする」くらいにしてと。おお、サービスアカウントIDが勝手に入力されました。そして、選択すると、おお、内容説明がポップアップした上に、複数選択できるのですね!とりあえず進めるって、必要ですねぇ。悩みが減りました。クエリ実行するためには、BigQueryユーザーを選ばないといけないようです。BigQueryデータ閲覧者はデータセットを表示することができるけど、クエリは発行できない、ということですね。
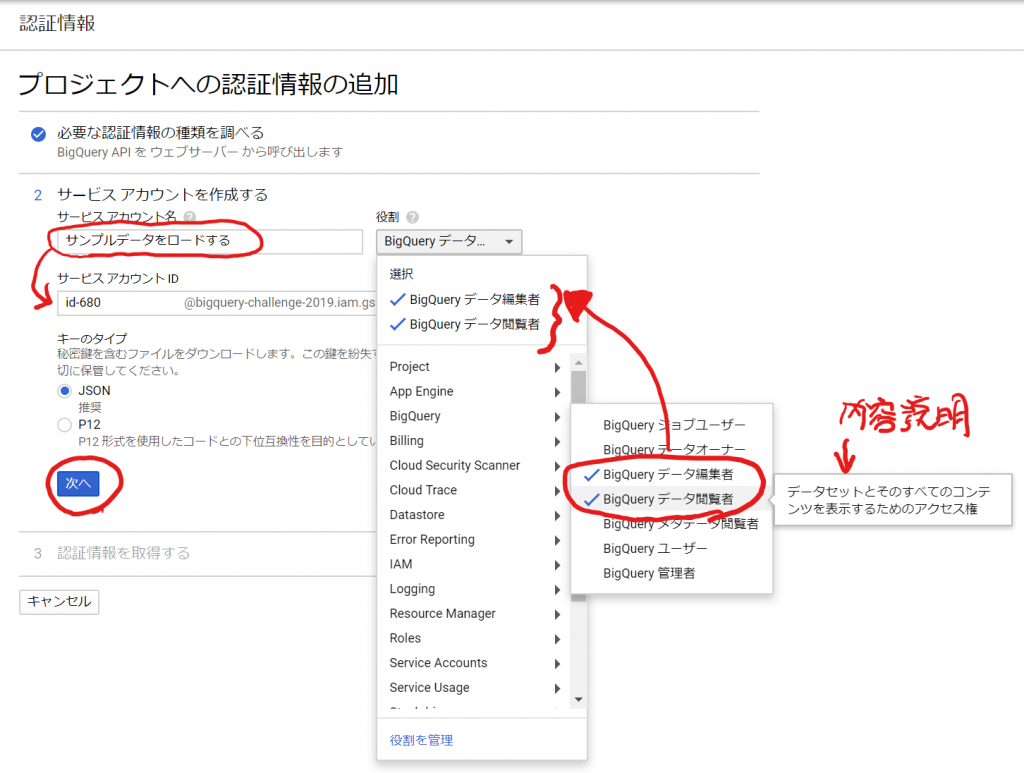
「キーのタイプ」は、たぶんデフォルトの「JSON」のままでよいでしょうね。「次へ」ボタンをクリックします。
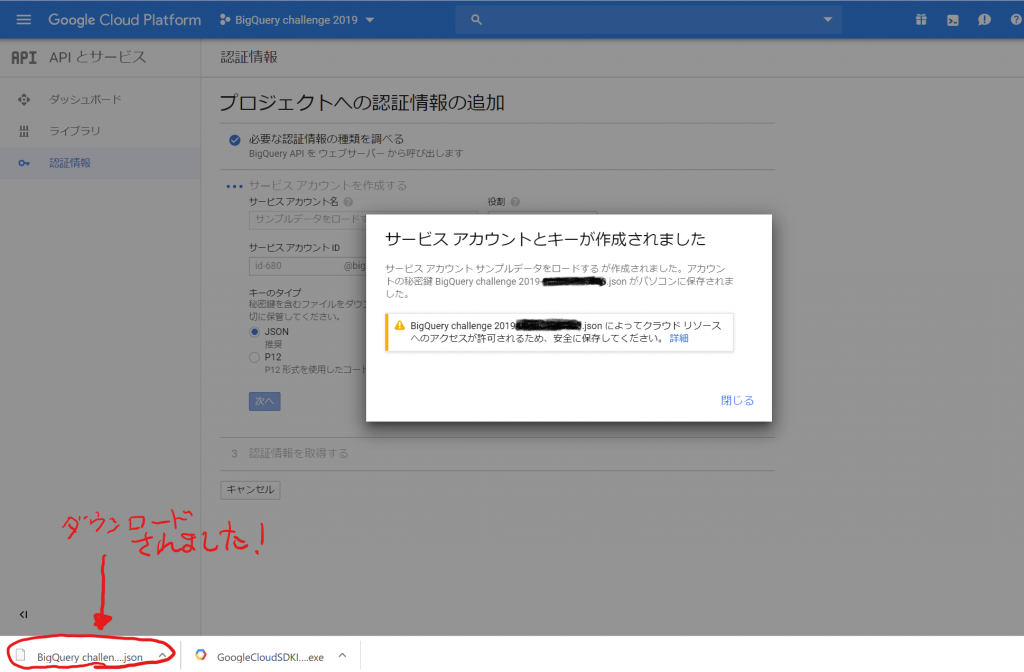
おお、自動でファイルがダウンロードされてしまいました。このJSONのファイルを利用するのでしょうか。「閉じる」をクリックします。
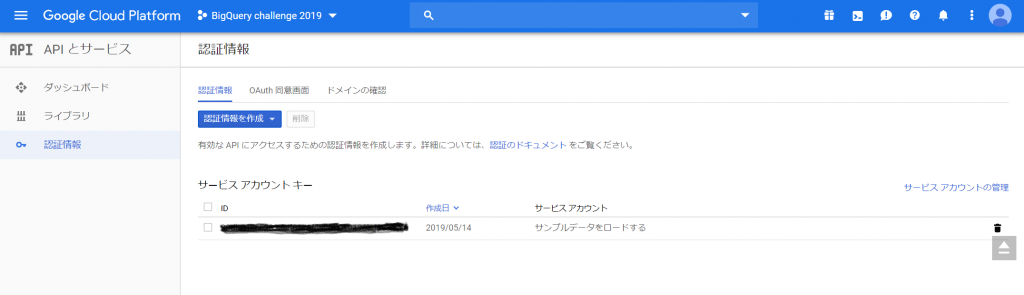
すると、認証情報のページが出てきて、どうやら「サービスアカウントキー」というものができたようです。む~、とりあえずこれでBigQuery APIが有効になった、ということでしょうか。
そういえば、前回のエントリーでCloud SDKをインストールしたけど、動作確認してませんでしたね。クイックスタートにも書いてありましたが、確か、bqコマンドが使えるはずですね。試しに実行してみます。
bg show bigquery-challenge-2019:books.books
失敗しました。。。「Not found: Dataset」ということですね。もしかしたら、大文字小文字を気にするのかもしれません、ということで、再度入力します。
bg show bigquery-challenge-2019:BOOKS.BOOKS
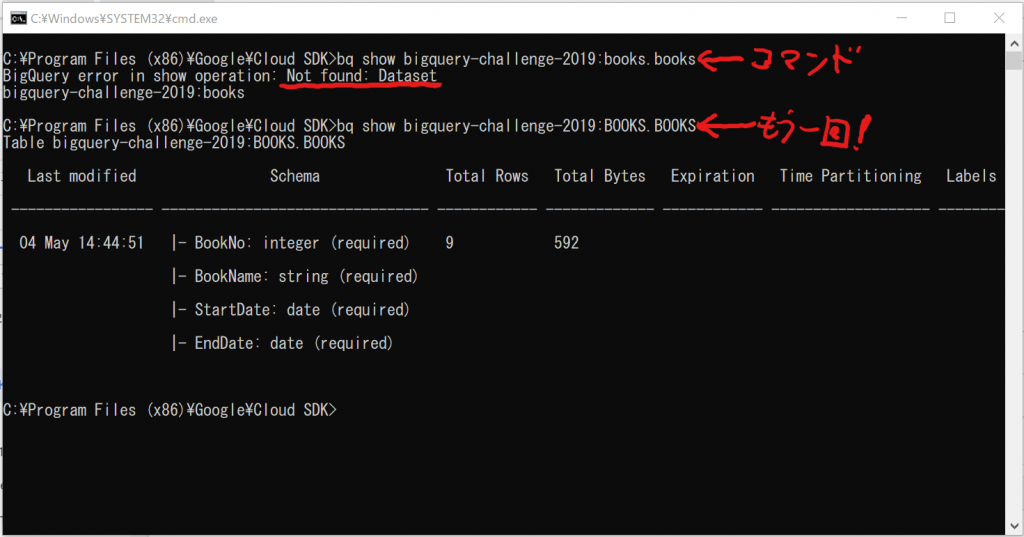
おおっ、出ました!成功したよ~!!
大したことはしていないんだけれど、うれしいですねぇ。BigQueryのテーブル名は大文字小文字を気にする、ということがわかりました。今後、気を付けます。
クイックスタートは続けてクエリを発行していますが、今回ぼくはクエリを実行する権限を与えていないつもりなので、失敗するのかも。ちょっとやってみます。
bq query "SELECT * FROM bigquery-challenge-2019:BOOKS.BOOKS"

予想通りエラーになりましたが、エラー内容が予想と違いましたねぇ。予想外に”-“が登場したと言っています。そういえば、演算のマイナスとの区別ができないから、テーブルを指定するときには括弧「[]」でくくること、という記述がどこかにあったような気がしますね。(追記:オライリー・ジャパンの『Google BigQuery』P.219 7.2 BigQueryのクエリ言語 のところに記述がありました。ISBN978-4-87311-716-4)ちょっと試しにやってみます。今度は想定通りのエラーになるかな?
bq query "SELECT * FROM [bigquery-challenge-2019:BOOKS.BOOKS]"
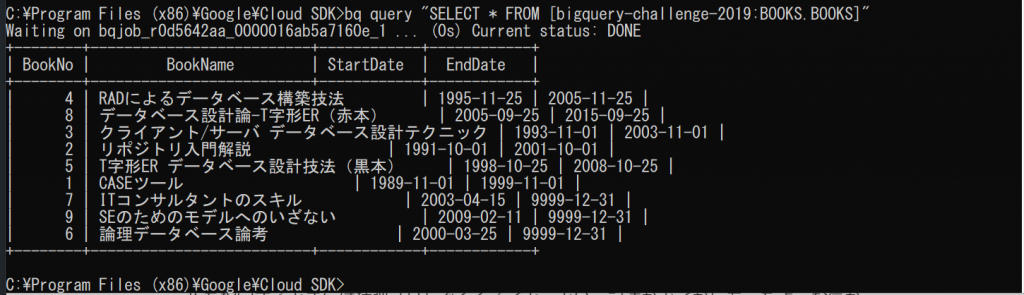
あら、想定外にデータが取得できてしまいました。そういえば、さっきダウンロードしたJSONのファイル、何にも指定していないよね。なるほど、ということは、bqコマンドの承認は、前回のエントリーでSDKをインストールしたときにやったものが有効になっているのですね。(あれです、’gloud init’を実行して、ログインして承認したやつですね!)
ええと、ということは、BigQueryのAPIを有効にしようと一生懸命やったこと、って、無意味だったのかな。。。?
はい、気を取り直して、新しく書籍のデータを作って入れてみます。
C:\work\NEW_BOOKS.csv 10,やさしいみつのりさんのデータベース,2020-05-14,9999-12-31 11,きびしいみつのりさんのデータベース,2021-05-14,9999-12-31
コマンドは、以下の通りです。「–noreplace」オプションを付けると、テーブルに追加してくれるそうです。上書きしたい場合は「–replace」で、何もつけなければ、テーブルが空の場合にのみ書き込みされるということですね。「–source_format」で指定できるフォーマットは、「CSV、AVRO、PARQUET、ORC または NEWLINE_DELIMITED_JSON です。」と、書いてありますね。CSVとNEWLINE_DELIMITED_JSONしか分かりません。(汗)ええと、いつか余裕が出てきたら、他のフォーマットも調べてみたいと思います。
bq load --noreplace --source_format=CSV BOOKS.BOOKS C:\work\NEW_BOOKS.csv
さて、実行してみます。

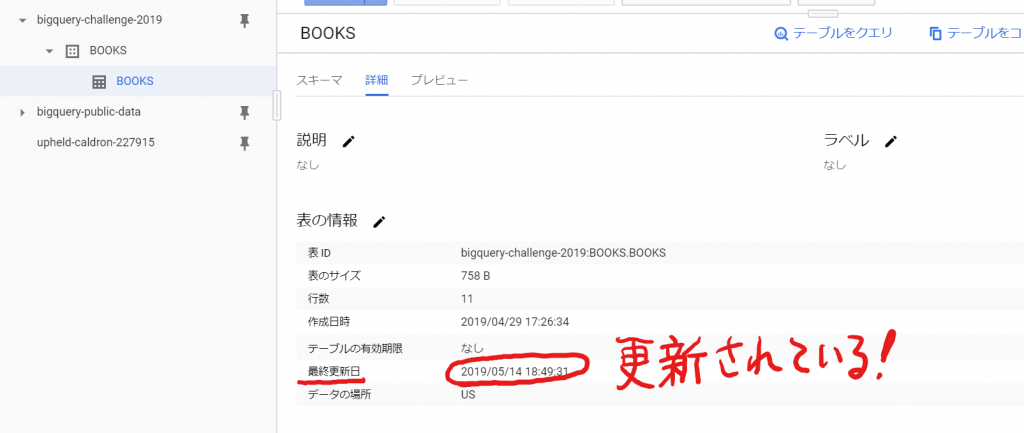
おお、なんか成功したっぽい!ほら、タイムスタンプが変わってるし!
データも、ほら、、、
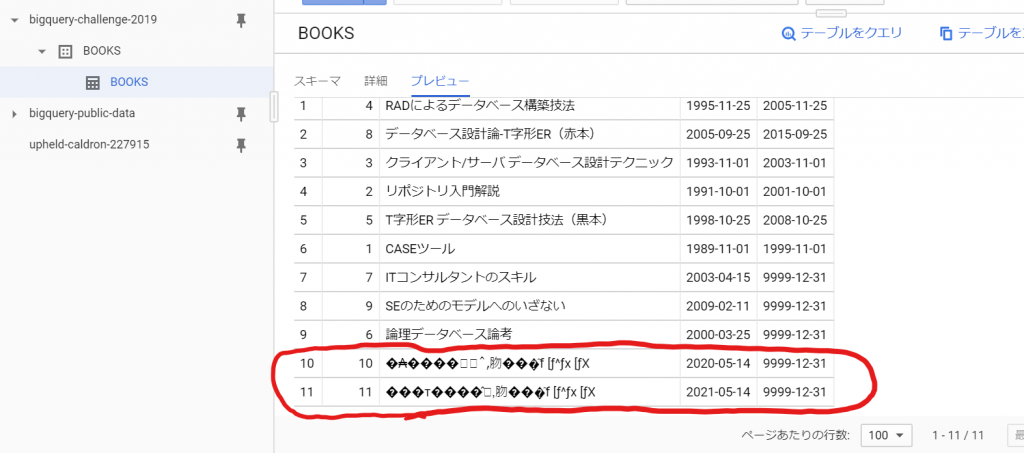
ぐはっ!!文字化けしてる。。。(笑)
そういえば、確かUTF-8にしないとダメだって、どこかに書いてあった気がしますねぇ。やっと終了、って、思ったのに~♪
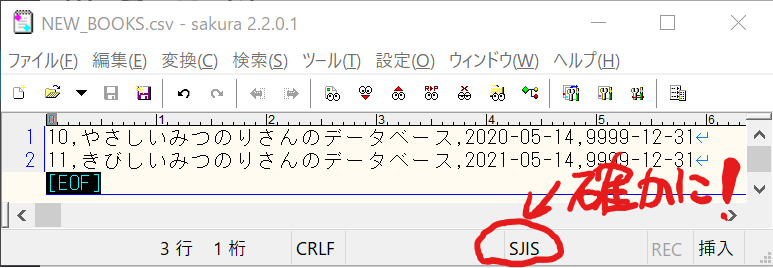
おお、確かにSJISになってます。サクラエディタの文字変換機能でSJISをUTF-8に変換して、再度コマンドを実行して確認してみます!
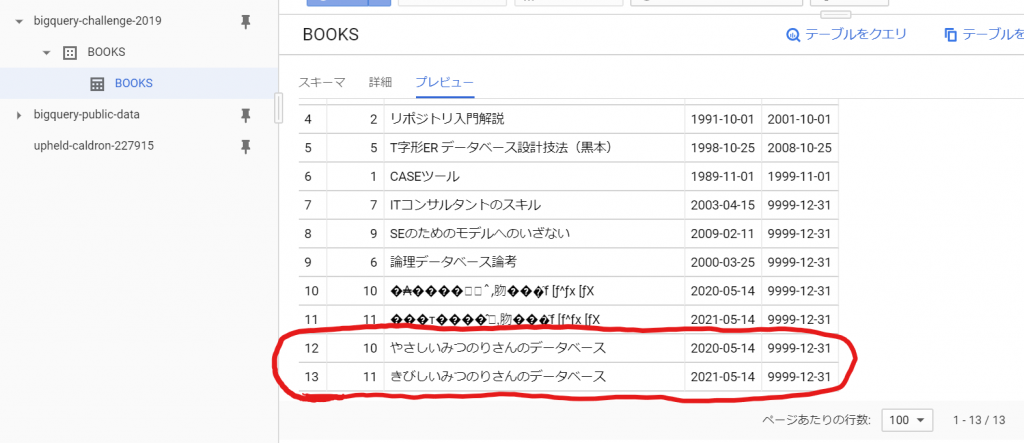
やっとこ、できました!
でも、なんだろう、この書名は、ねぇ。。。(笑)
これで、実現方法は完了ですね。サーバーでCSVファイルをUTF-8で作成して、bqコマンドを実行するバッチファイルをスケジューラに登録すれば、自動でデータロードできるところまで確認できました。注意点は文字コードを気にすることと、’cloud init’の権限ですね。テストはこれで動いたということで問題ないですけど、本番環境のサーバーでは、どのユーザで権限を設定するのか、というのが課題になりそうです。
BigQueryのAPI、有効にしたのが無意味だったか確認してみます。先ほど作成した認証情報を削除してみます。
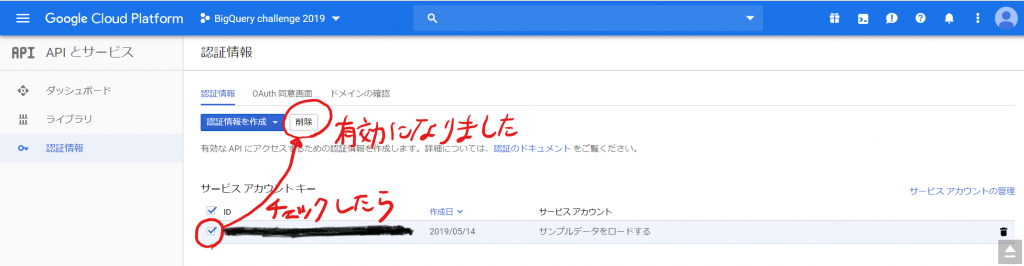
「削除」ボタンをクリックします。
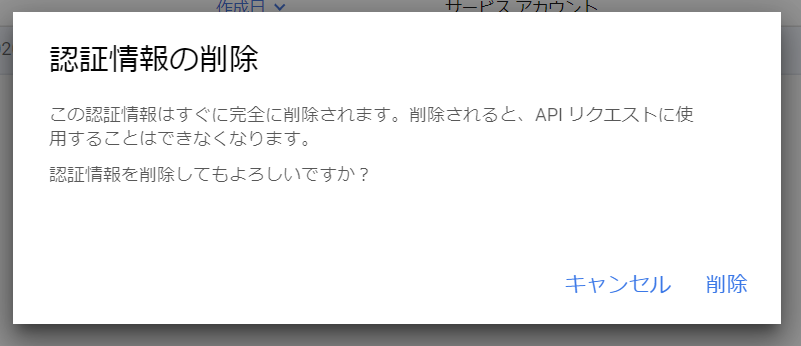
おお、脅されますねぇ。脅しには屈しませんよ!「削除」をクリックします。数秒で消えましたので、再度データをロードしてみます。問題なく動きましたので、BigQuery APIの利用は、データのロードには関係ない、ということがわかりました。やりたいことはできるようになったけど、プロの仕事としては、いまいちだなぁ。GCPをプロとして使っていくためには、権限、認証を理解することが課題ですね。またそのうち調査したいと思います。では、今回のエントリーはこのあたりで終了とします。