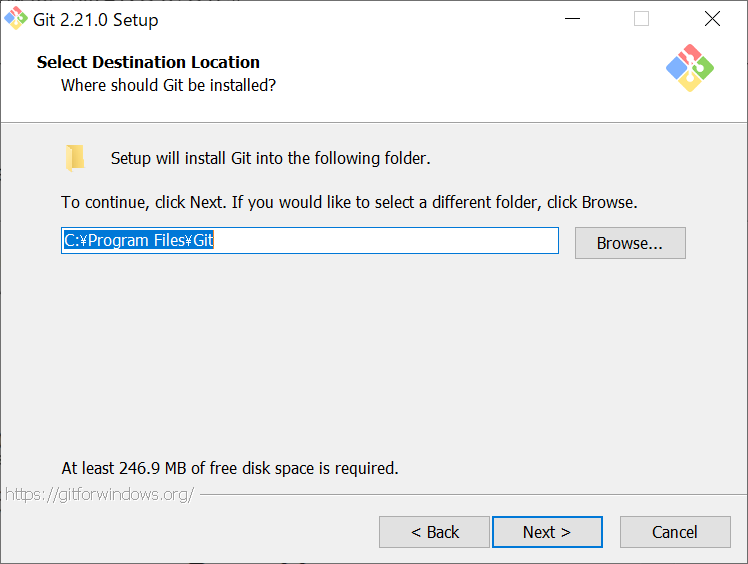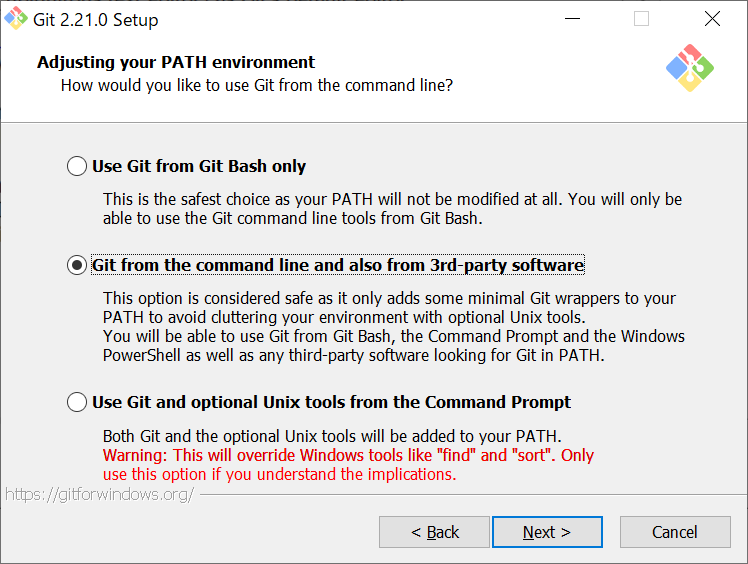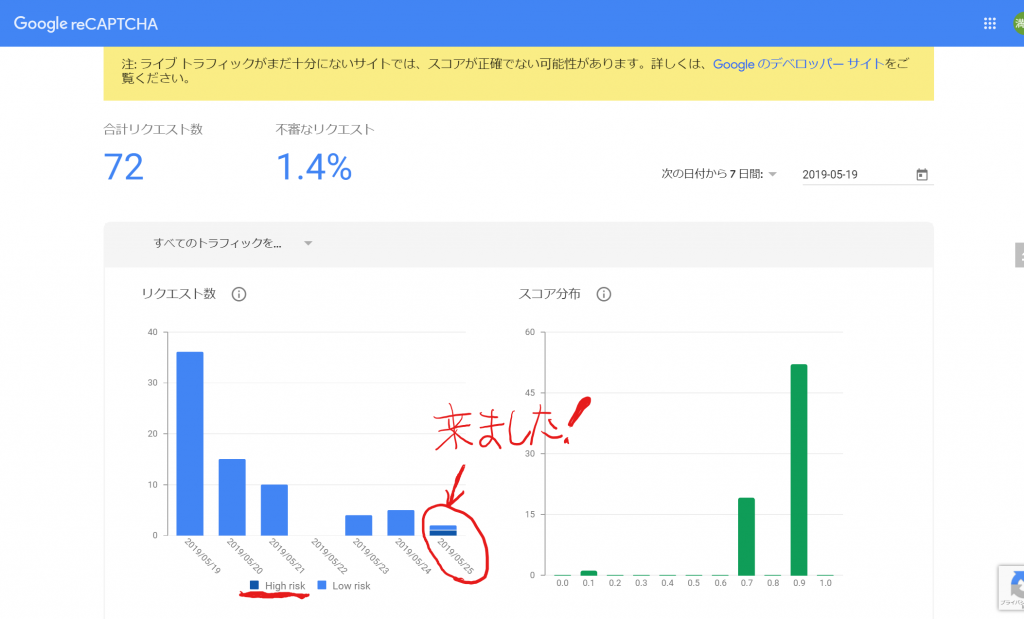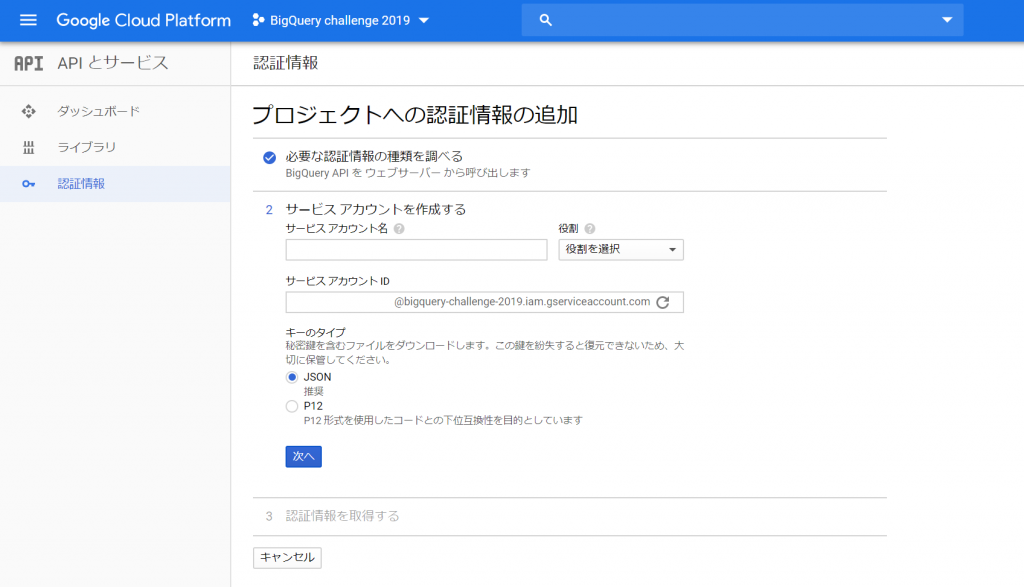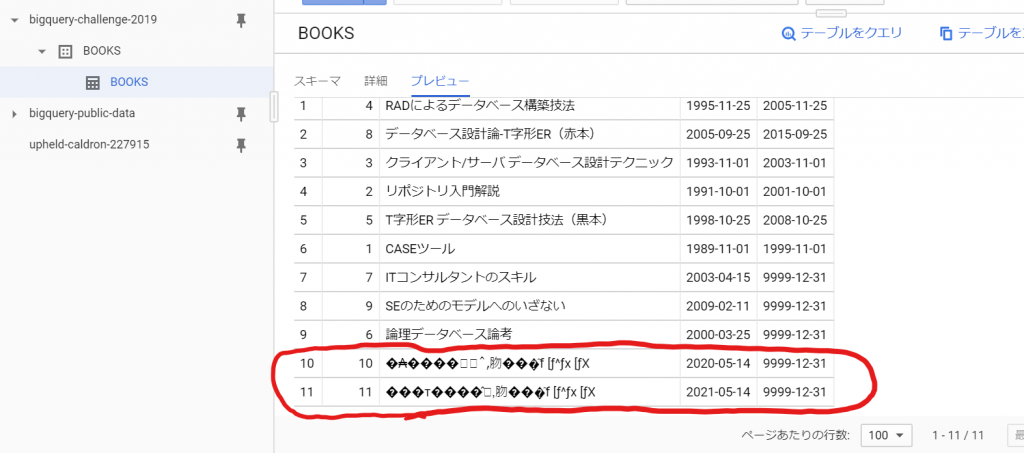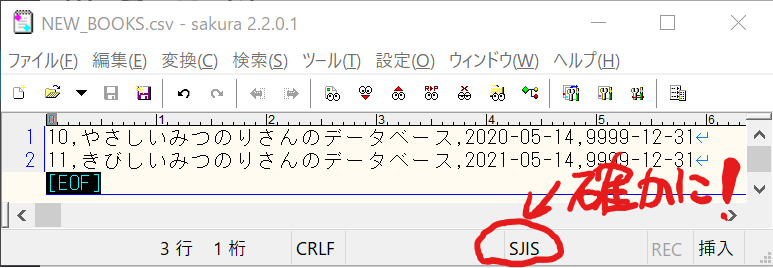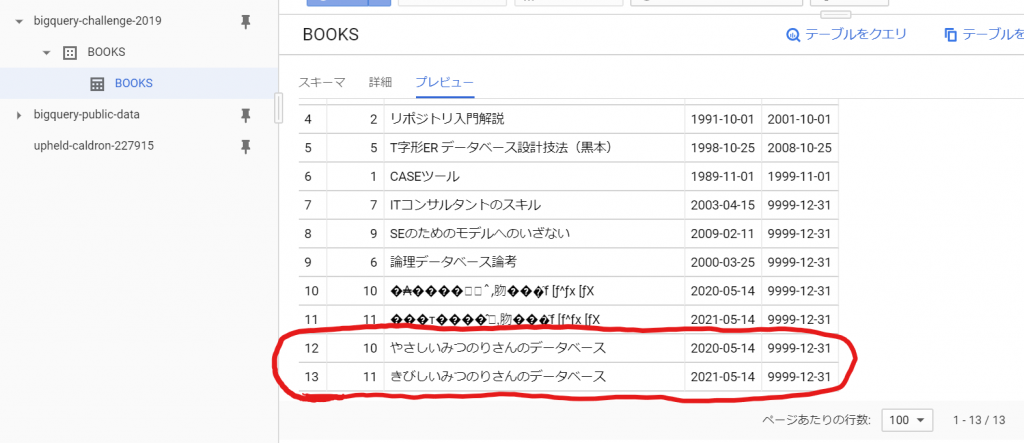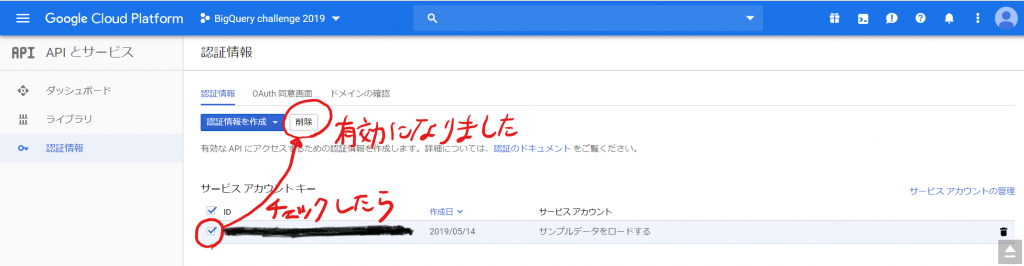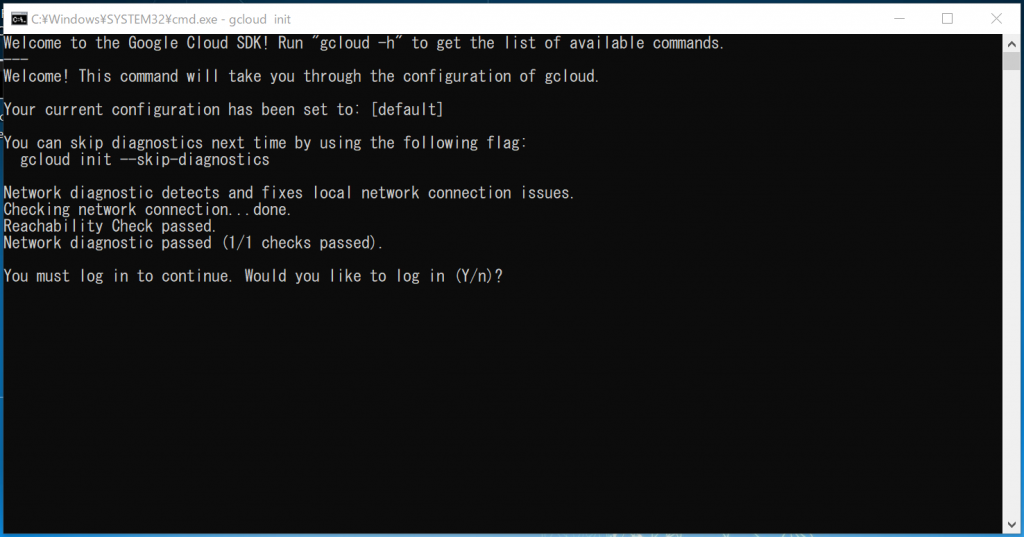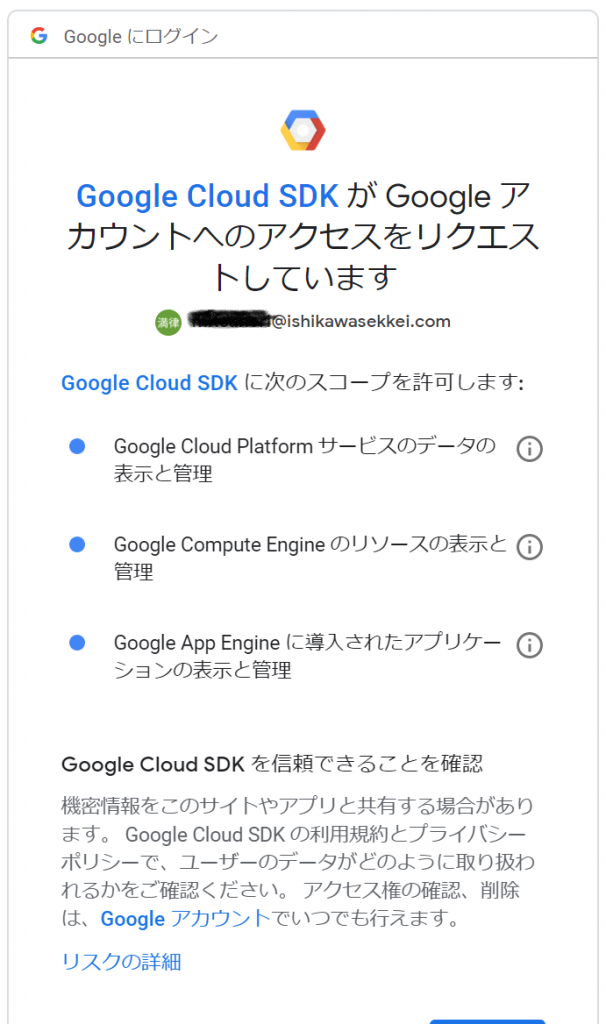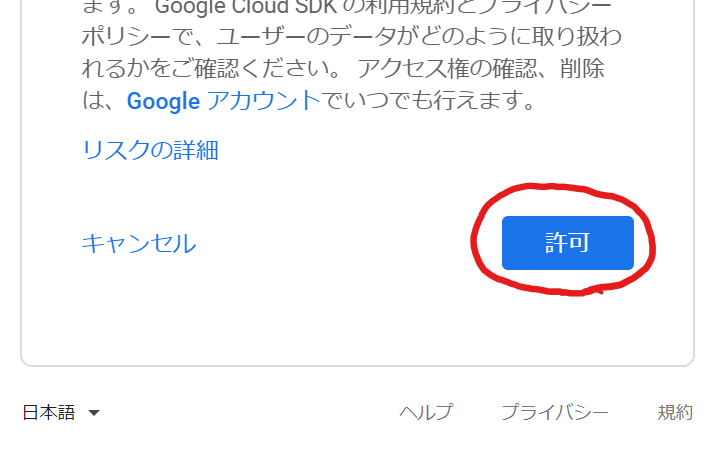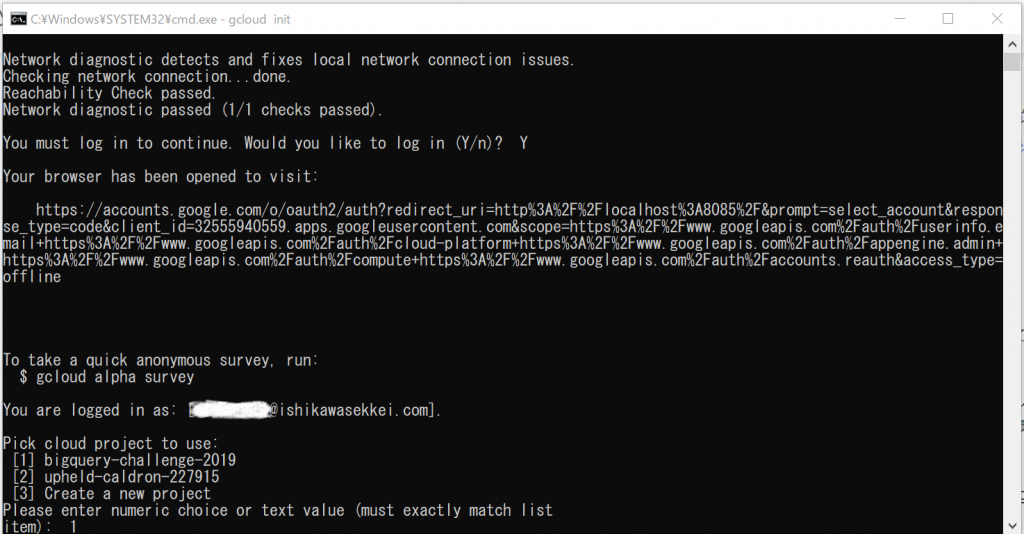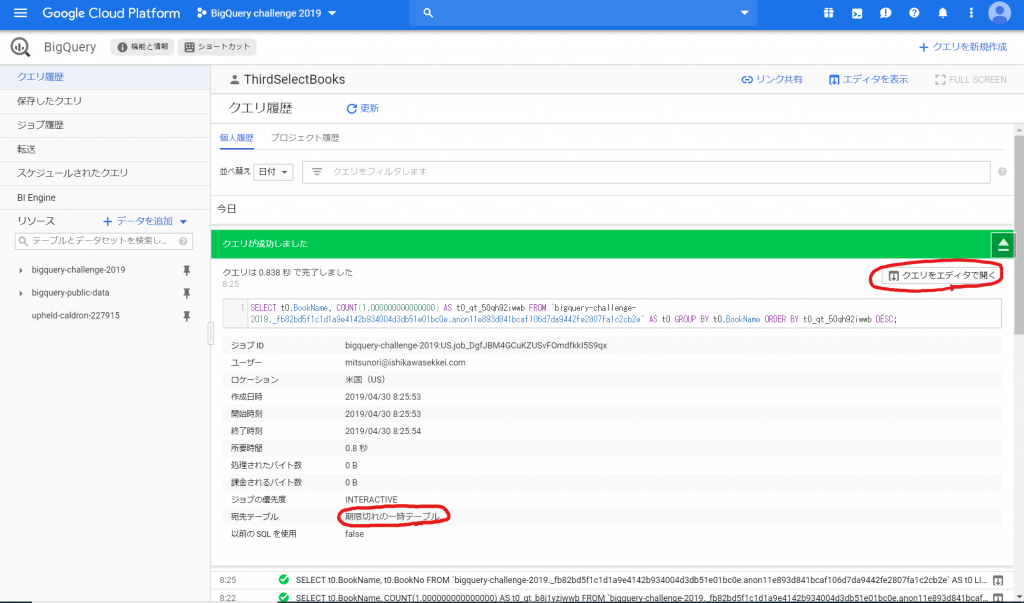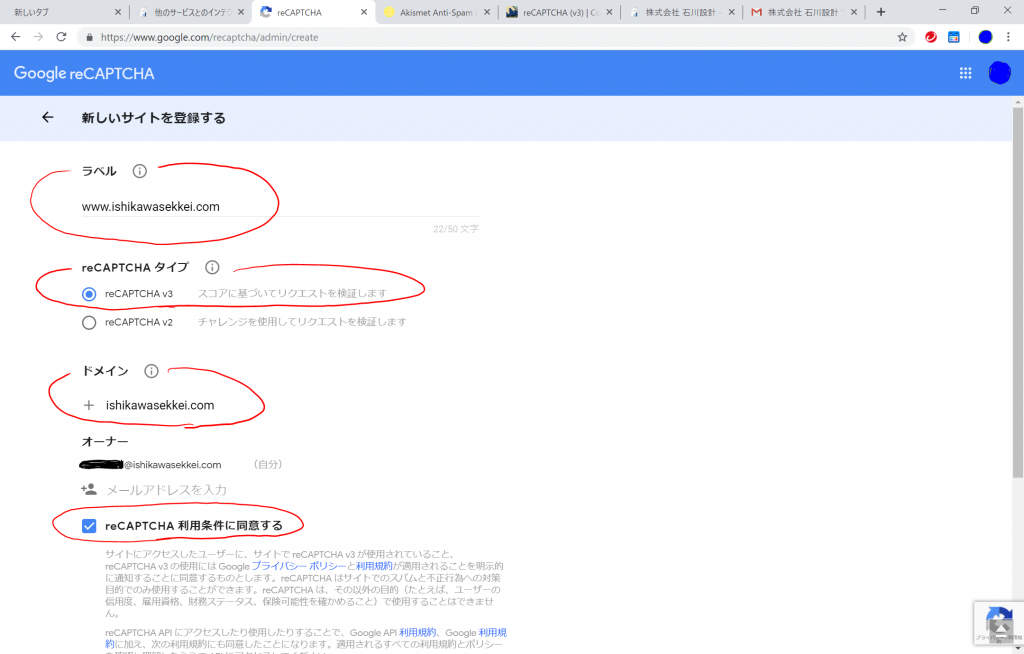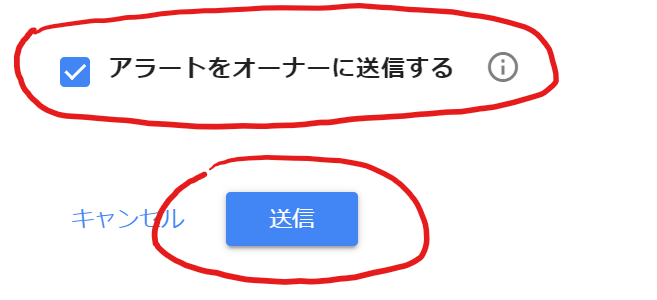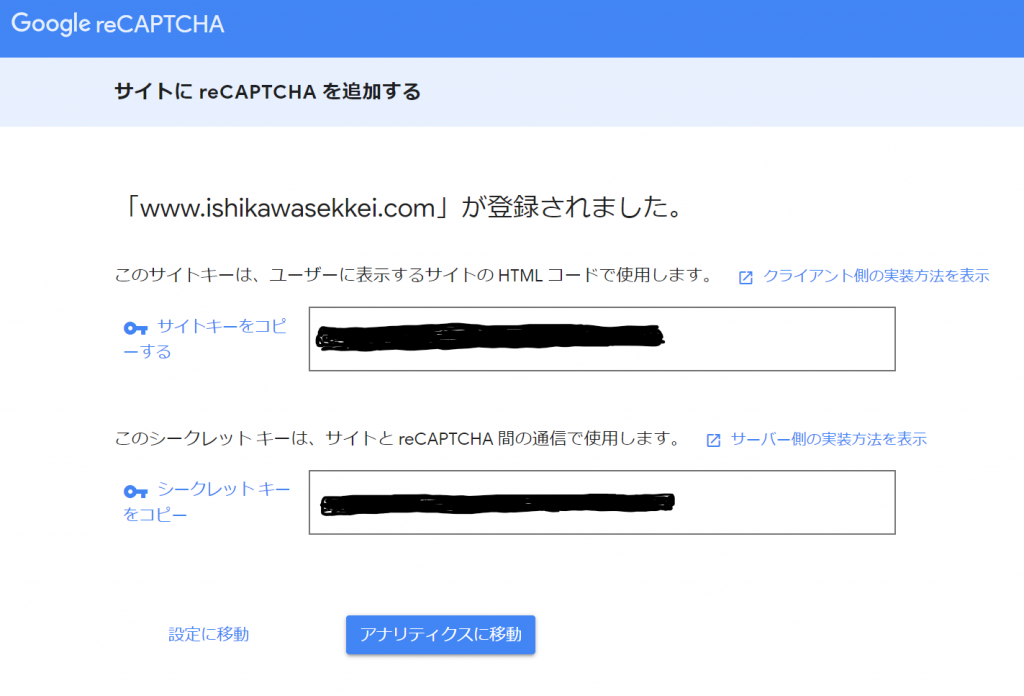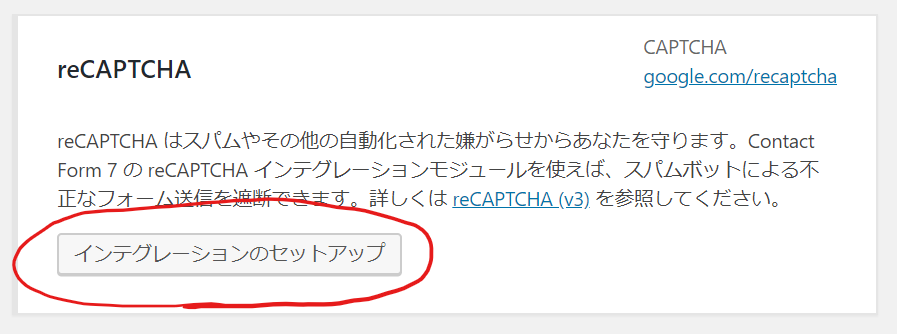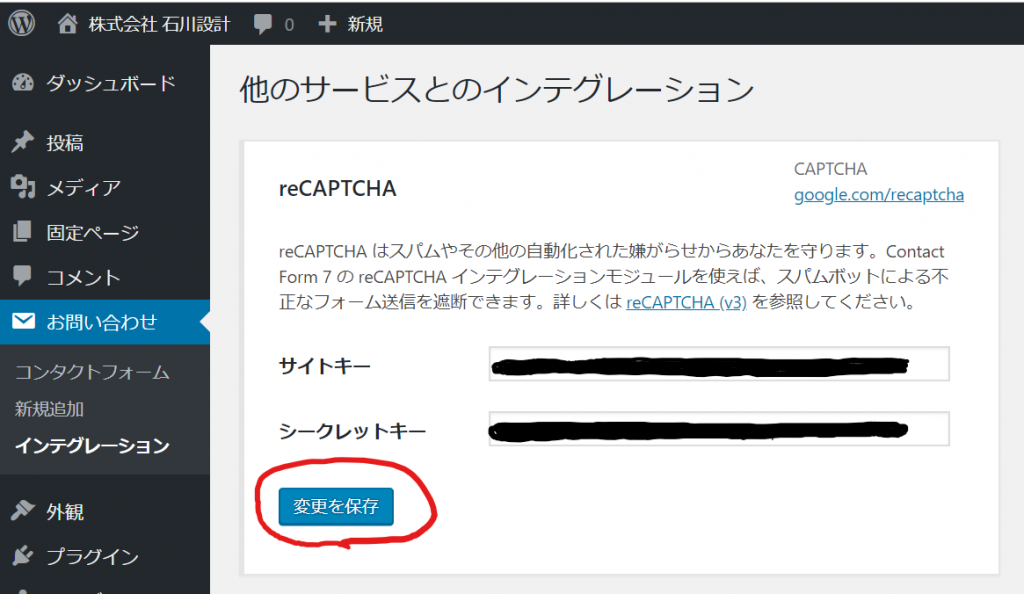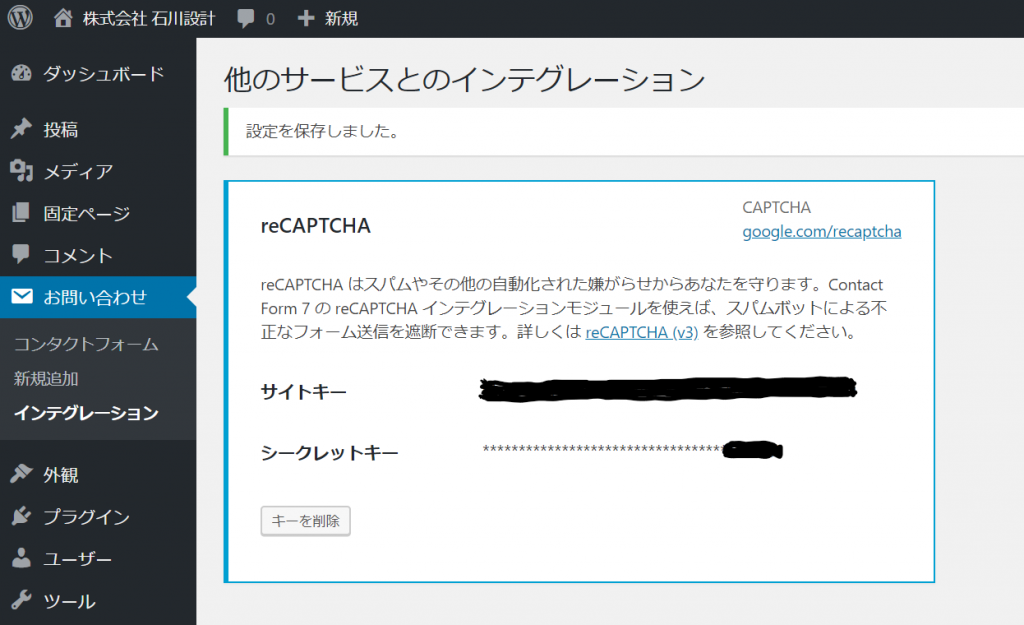
前回の続きです。次にやらないといけないことは、PATHの設定です。

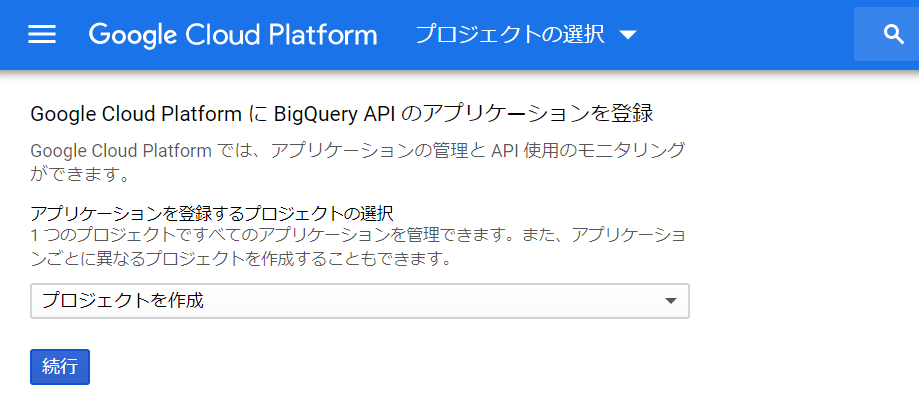
ユーザー変数のPATHを設定するために、Windows画面左下の「ここに入力して検索」のところへ「env」とキー入力します。
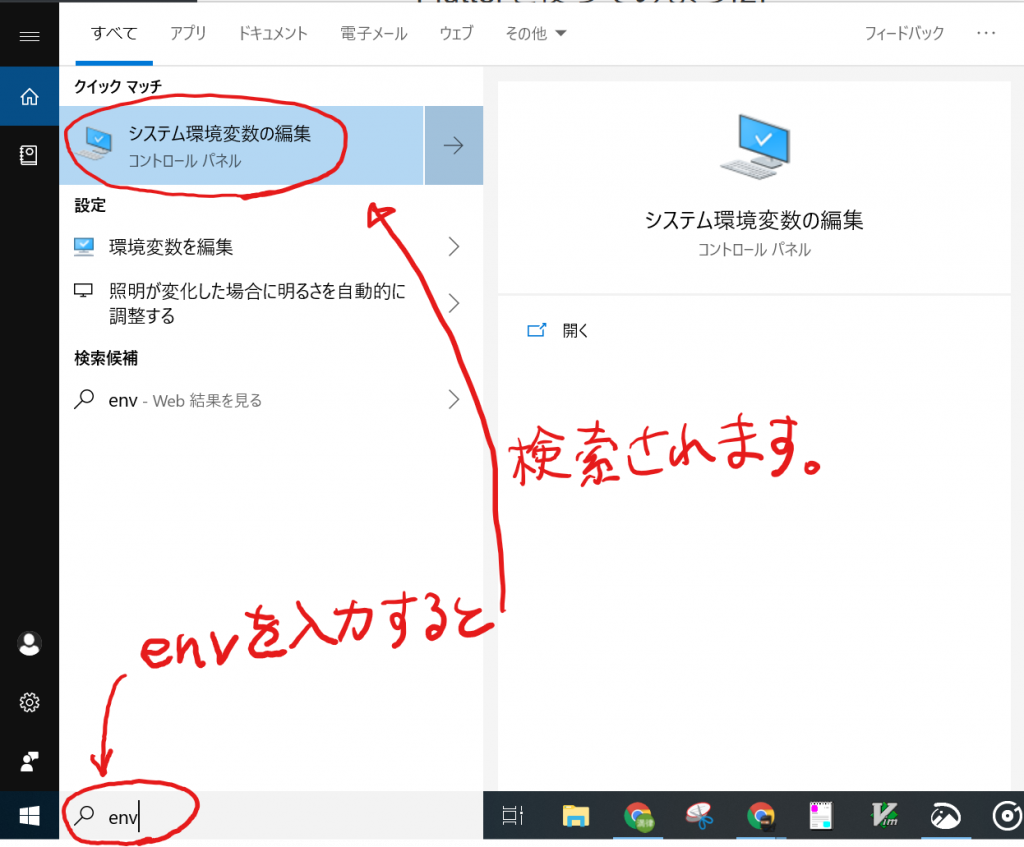
すると「システム環境変数の編集」が検索されてきますので、クリックします。
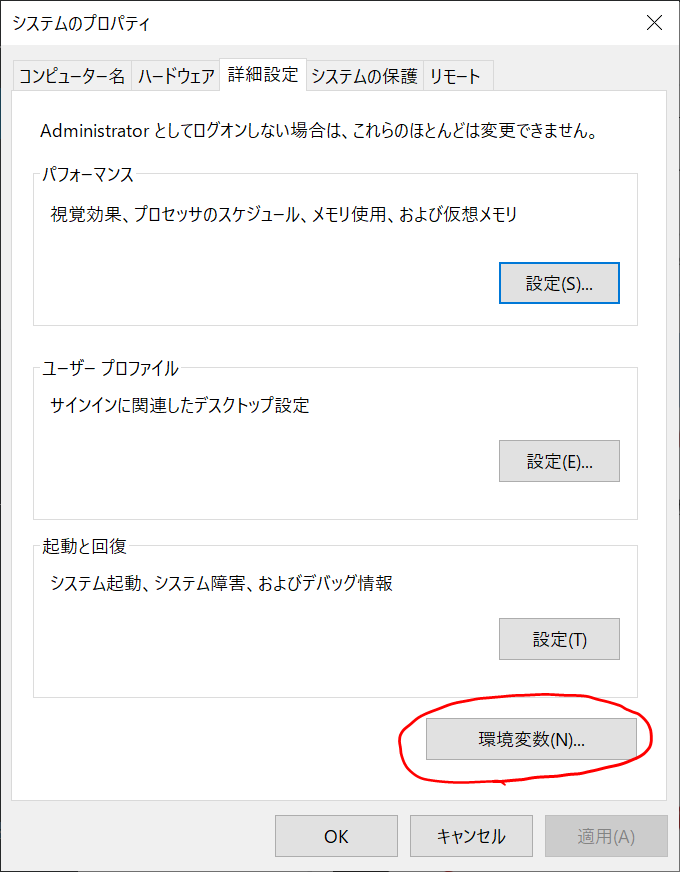
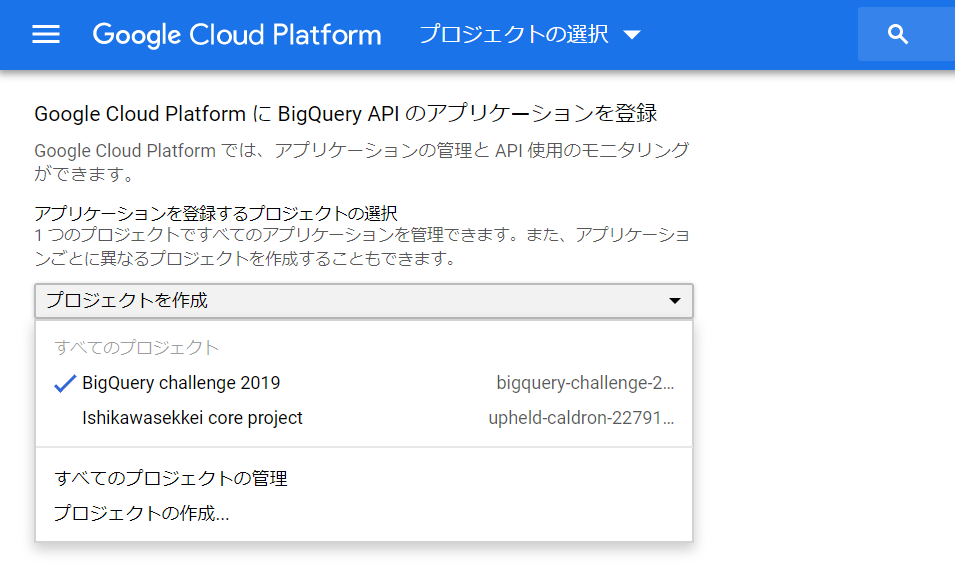
「環境変数(N)…」をクリックします。
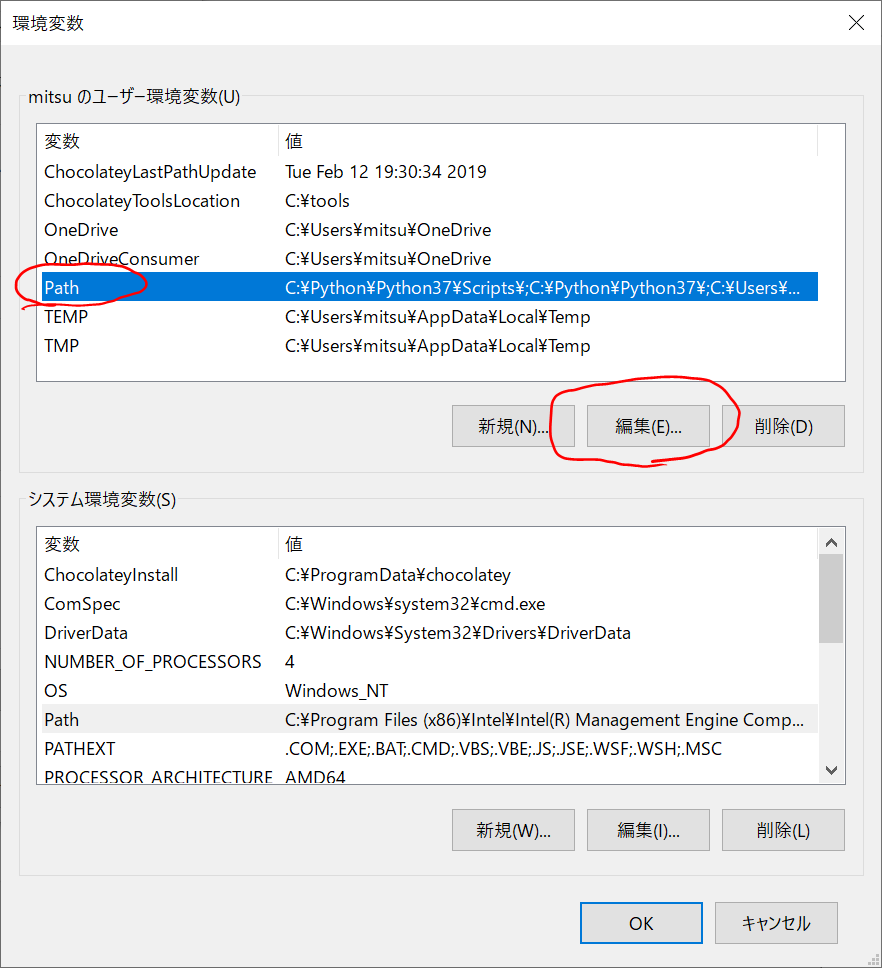
「Path」を選んで「編集(E)…」をクリックします。
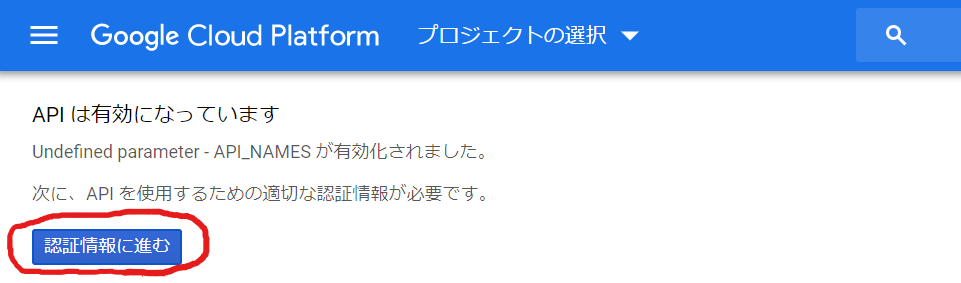
「新規(N)」をクリックします。
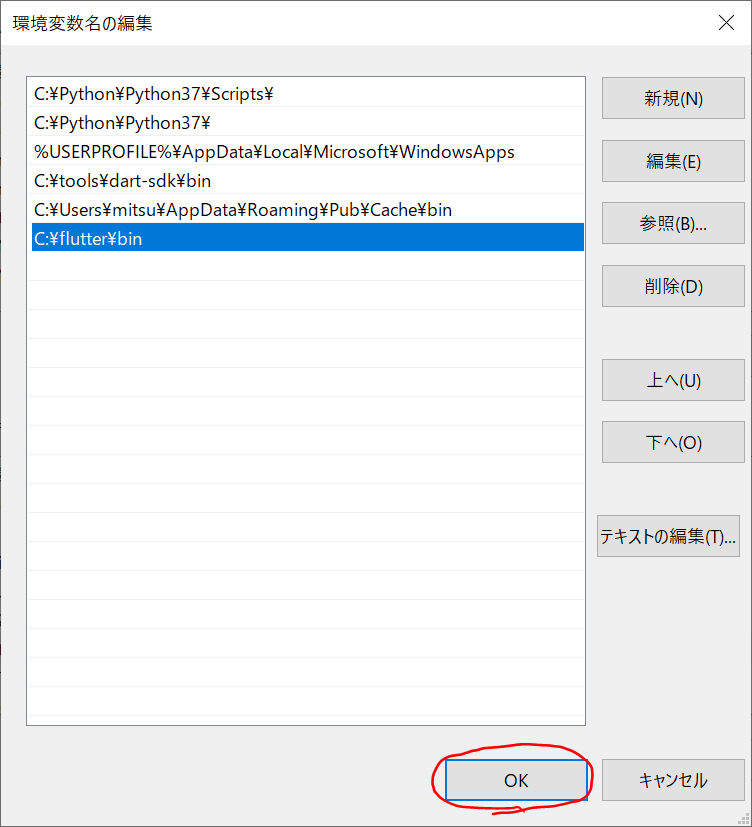
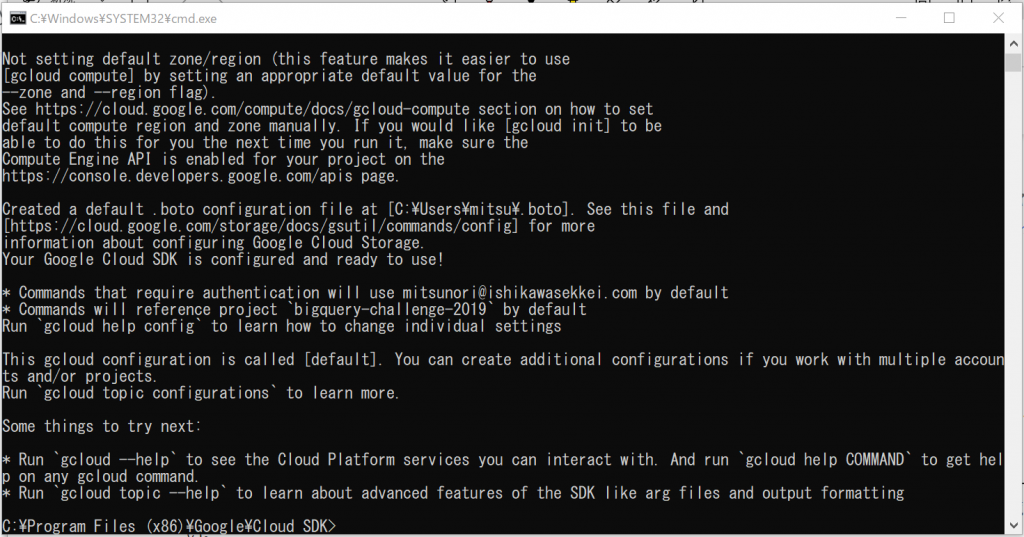
「C:\Flutter\bin」を追加して「OK」を次々とクリックしてPATHの追加は終了です。
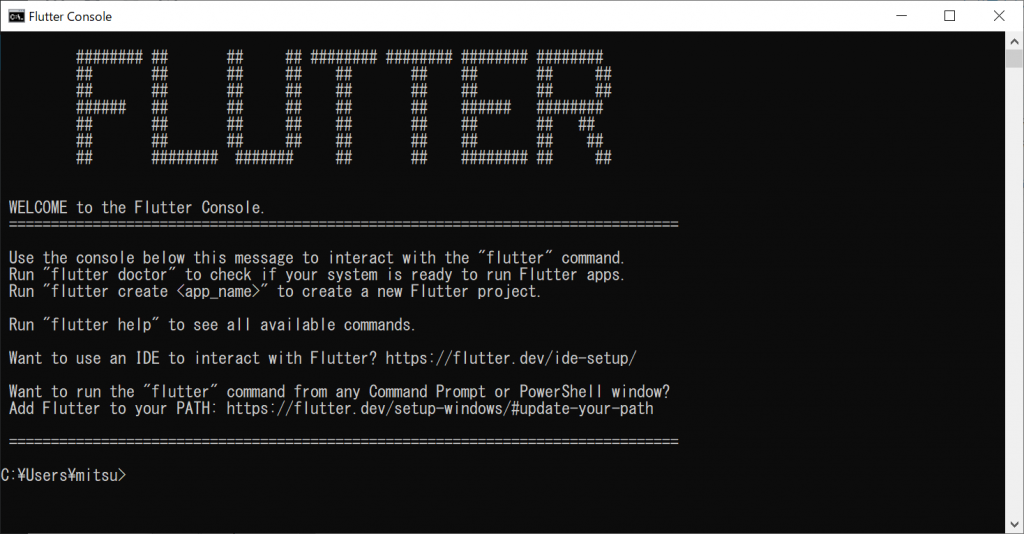
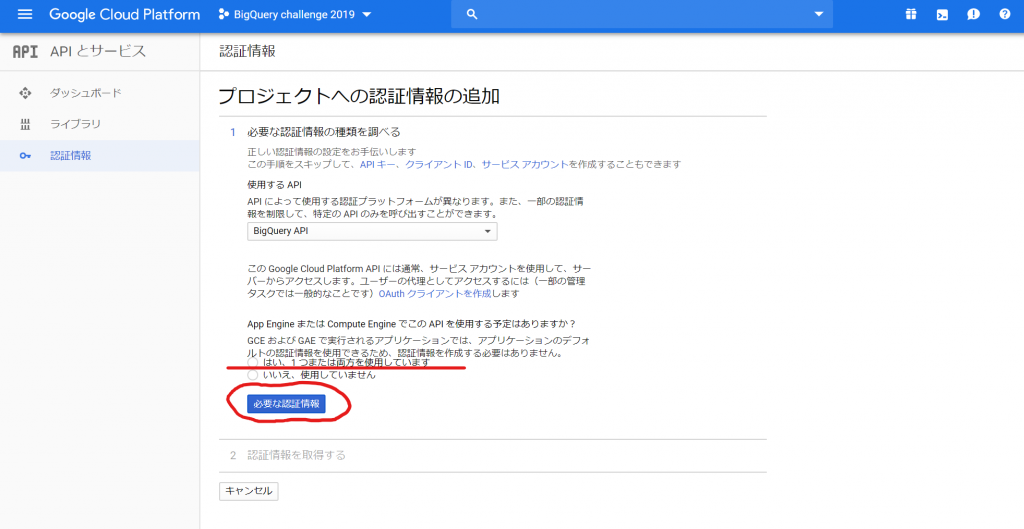
次は、「flutter doctor」コマンドを実行せよ、ということですので、実行してみます。
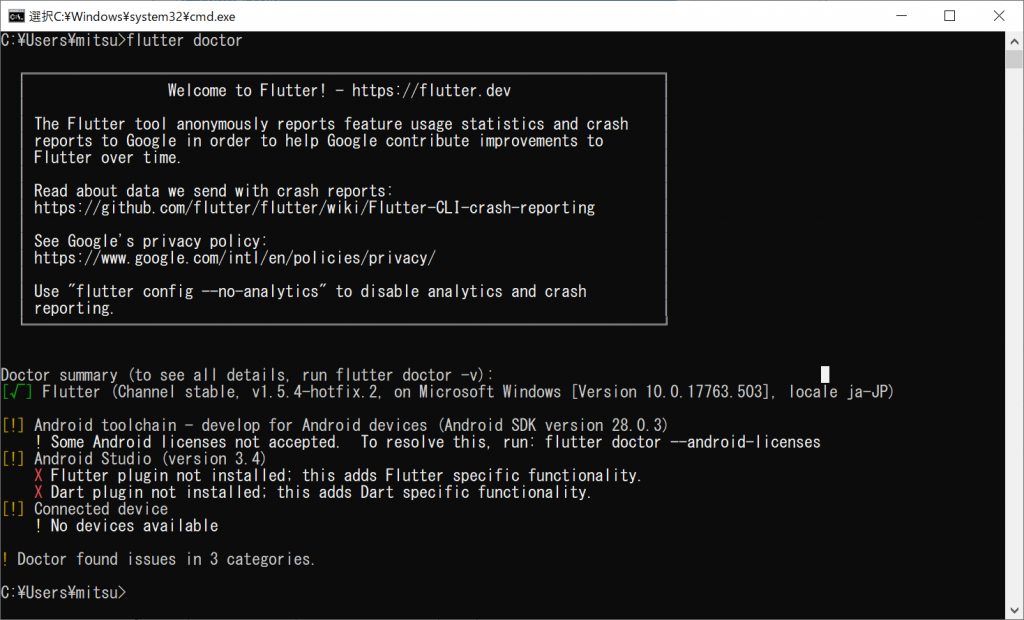
しばらくグルグルしていましたが、メッセージが出てまいりました。Flutterはちゃんとインストールされているようです。Android toolchainの中で、いくつかのライセンスが受け付けられてなくてダメ、と言われております。解決するためには「flutter doctor –android-licenses」を実行してね、と言われましたので、実行してみます。そういえば、フライイングして、AndroidStudioはインストールしておいたのでした。こちらは別途記事をアップしたいと思います。

ここで初期値のままエンターキーを押すと終了しました。ま、当たり前ですけど。再度実行して、このタイミングで「y」を入力してからエンターキーを押すと、たくさんメッセージが出力されて、またしても、「y/N」を聞かれます。
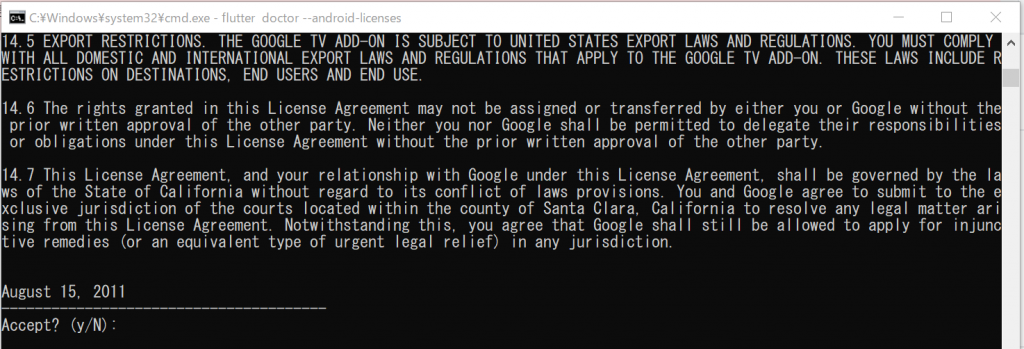
上の方に戻って見てみますと、「The Google TV Add-on for the Android Software Development Kit」のソフトウエア利用許諾契約が5個のうちのひとつ目ということで出力されていました。たぶんテレビのアドオンは使わないですねぇ。エラーじゃなくて警告ということだから、全部そのままでいいような気がしてきました。でも、後から問題になったときに問題を発見するのは難しいだろうなぁ。と、いうことで、今回はすべて許諾をよく読んでひとつずつ「y」を入れて許諾していくことにしようと思います。
- The Google TV Add-on for the Android Software Development Kit License Agreement
- The Android Software Development Kit License Agreement
- The Glass Development Kit License Agreement
- Intel (R) Hardware Accelerated Execution Manager End-User License Agreement
- MIPS Technologies, Inc. (gMIPSh) Internal Evaluation License Agreement for MIPS Android
以上、順番に許諾していきました。
そして、次の2つに対応したいと思います。
[!] Android Studio (version 3.4)
X Flutter plugin not installed; this adds Flutter specific functionality.
X Dart plugin not installed; this adds Dart specific functionality.
FlutterホームページのGet Started - Set up an editor に書いてありました。
まずは、Android Studioを起動します。

しばらく待つと、「Welcome to Android Studio」画面が登場します。

はて、Fileメニューがありませんね。プロジェクトを作成していないからでしょうか。ConfigureをクリックしたらSettingsとPluginsがありました。
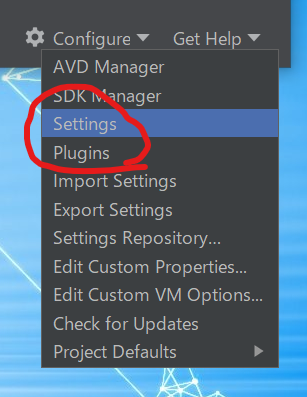
確認したところPluginsでも同じ画面にたどり着きましたので、Settingsの方がわかりやすいと思いますので、そちらの画面を採用します。
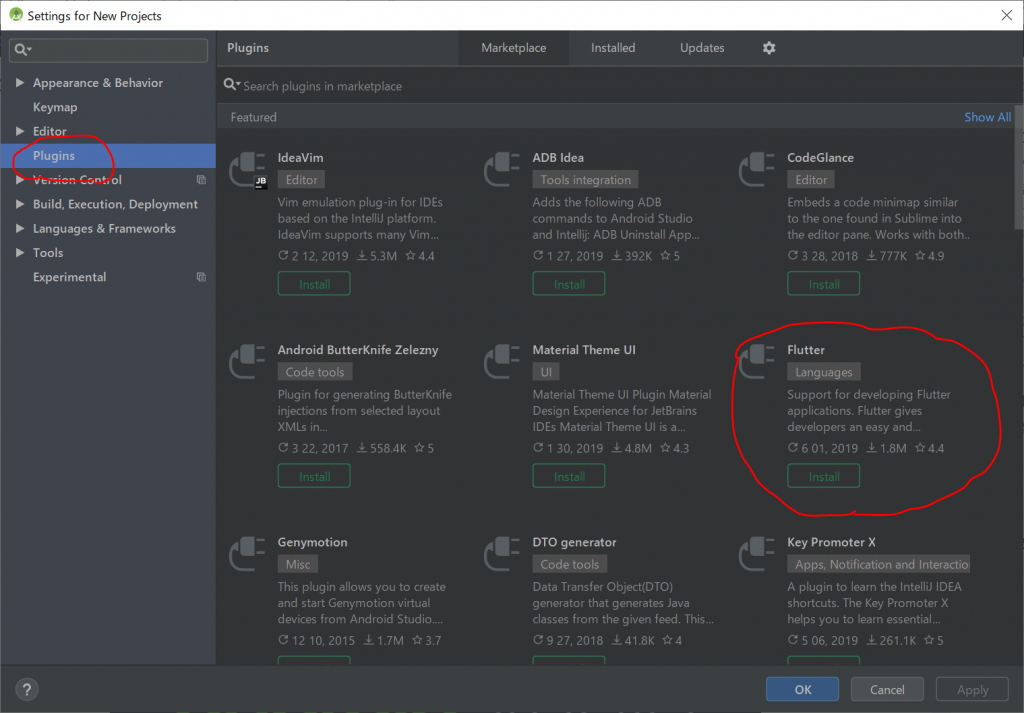
Flutterの項目の「Install」をクリックします。
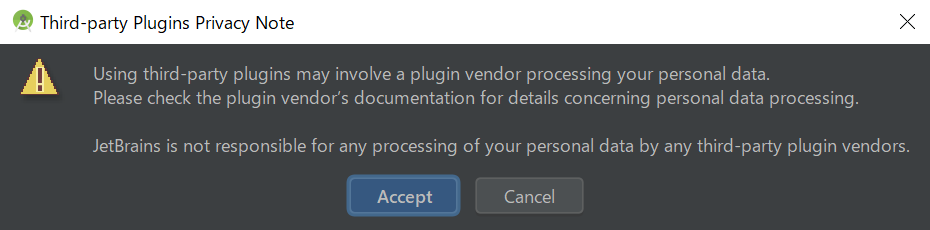
サードパーティのプラグインが個人情報を扱う方法についてはJetBrains社は全く関知しないのでちゃんとチェックしてくださいね、というメッセージが表示されました。「Accept」をクリックします。

「インストールしようとしているプラグインはDartのプラグインを必要としています。続けますか?」はい、当然、続けますよ。「Yes」をクリックします。
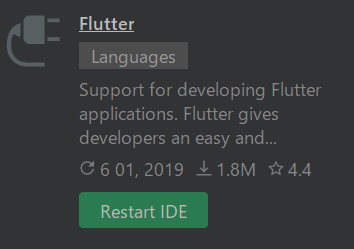
しばらく待つと、上記のようにボタンが「Restart IDE」に変わります。これをクリックしてAndroid Studioを再起動します。
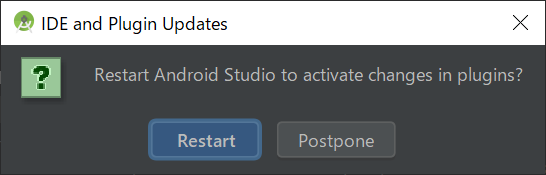
はい、「Restart」ですよ~。
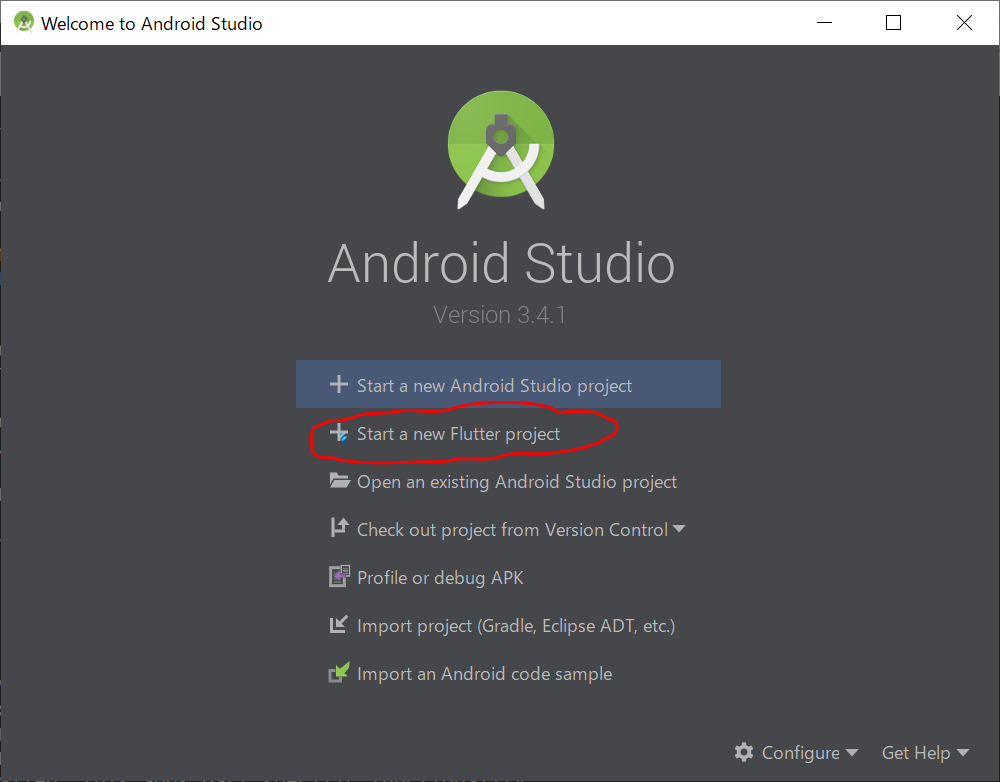
おっ、Flutter用のメニューが増えていますね。もう一度「flutter doctor」コマンドを実行してみます。
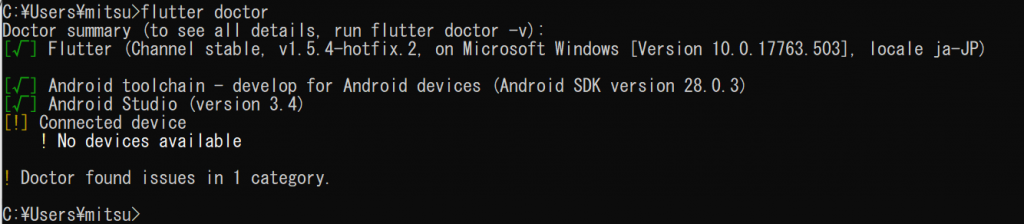
エラーは解決しました。Flutter入門には、「Flutter I18n」というプラグインもインストールしてね、と書いてありましたので、同様にインストールしておきました。日本語を扱うときに必要な国際化プラグインですね。
あとは接続デバイスですが、現在接続されているデバイスを表しているだけ、ということで、つなげば解消するということですので気にしないことにします。これでセットアップは概ね完了ですね。次回、プロジェクトを作って実際に動かしてみたいと思います。やっと実行できる~!!!